Spark SQL 是 Spark 用于处理结构化数据的一个模块,不同于 Spark RDD,Spark SQL 接口提供了更多关于数据的结构化信息,Spark SQL 会通过这些信息执行一些额外的优化操作。Spark SQL 提供了 SQL 和 DataSet 两种 API,二者底层使用的执行引擎相同,效率也一样,开发人员可以很容易地的在不同 API 之间切换,选择何种 API 要看哪种方式可以更自然地来表达给定的变换。
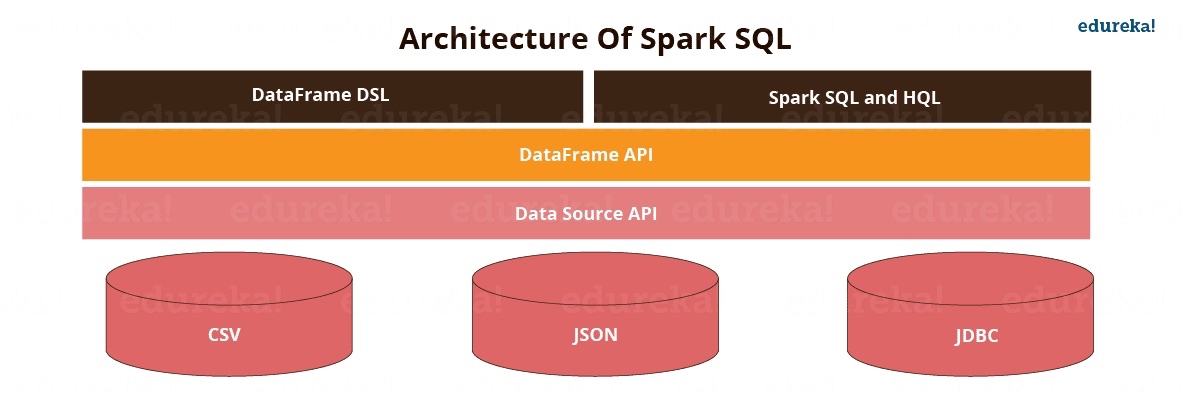
结构化 API
Spark SQL API 可以在模块 org.apache.spark.sql下查看:
常用的 API 模块:
- Spark SQL 数据类型:org.apache.spark.sql.types
- Spark SQL 函数:org.apache.spark.sql.functions
- Spark SQL DataFrame:,Dataset 的大部分 API 同样适用于 DataFrame
- Spark SQL Column:org.apache.spark.sql.Column
- Spark SQL Row:org.apache.spark.sql.Row
- Spark SQL Window:org.apache.spark.sql.Window
SQL
Spark SQL 的用法之一是执行 SQL 查询,它也可以从现有的 Hive 中读取数据,如果从其它编程语言内部运行 SQL,查询结果将作为一个 Dataset/DataFrame 返回。
表和视图与 DataFrame 基本相同,为我们只是针对它们执行 SQL 而不是 DataFrame 代码。
DataSet
Spark 结构化 API 可以细分为两个 API:有类型的 Dataset 和无类型的 DataFrame。说 DataFrame 是无类型的并不准确,它们具有类型,但是 Spark 会完全维护它们,并且仅在运行时检查那些类型是否与模式中指定的类型一致。而 DataSet 在编译时检查类型是否符合规范,DataSet 仅适用于基于 Java 虚拟机(JVM)的语言(Scala 和 Java)。
Dataset 是一个分布式数据集,它是 Spark 1.6 版本中新增的一个接口, 它结合了 RDD(强类型,可以使用强大的 lambda 表达式函数) 和 Spark SQL 的优化执行引擎的好处。Dataset 可以从 JVM 对象构造得到,随后可以使用函数式的变换(map,flatMap,filter 等)进行操作。Dataset API 目前支持 Scala 和 Java 语言,还不支持 Python, 不过由于 Python 语言的动态性, Dataset API 的许多好处早就已经可用了,例如,你可以使用 row.columnName 来访问数据行的某个字段。
DataFrame 是按命名列方式组织的一个 Dataset。从概念上来讲,它等同于关系型数据库中的一张表或者 R 和 Python 中的一个 dataframe, 只不过在底层进行了更多的优化。DataFrame 可以从很多数据源构造得到,比如:结构化的数据文件,Hive 表,外部数据库或现有的 RDD。 DataFrame API 支持 Scala, Java, Python 以及 R 语言。在 Scala 和 Java 语言中, DataFrame 由 Row 的 Dataset 来 表示的。在 Scala API 中, DataFrame 仅仅只是 Dataset[Row] 的一个类型别名,而在 Java API 中, 开发人员需要使用 Dataset
来表示一个 DataFrame。
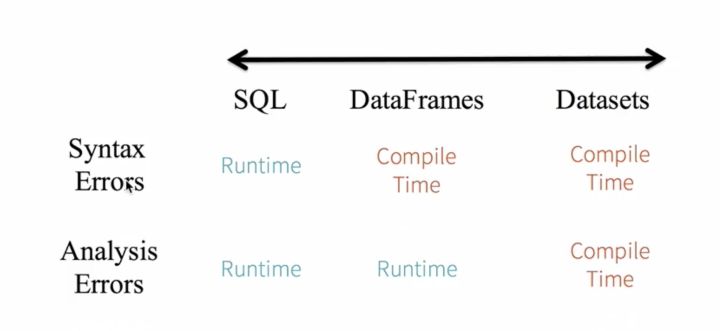
下图对比了 SQL、DataFrame 和 DataSet 三种 Spark SQL 编程方式错误检查机制:
- 对于 SQL 来说,编译的时候并不知道你写的对不对,只有到运行的时候才知道;
- 对于 DataFrame,语法错误可以在编译时发现(比如将 select 写错),但分析错误只有到运行时才能知道(比如将字段名写错);
- 对于 DataSet,在编译阶段就可以发现语法和分析错误,即静态类型和运行时类型安全。
在大多数情况下,您可能会使用 DataFrame。对于 Scala-Spark,DataFrame 只是类型为 Row 的数据集,Row 类型是 Spark 内部优化表示的内部表示形式,这种格式可以进行高度专业化和高效的计算,而不是使用 JVM(可能导致高昂的垃圾处理和对象实例化成本)。对于 PySpark,一切都是 DataFrame。
DataFrame VS RDD
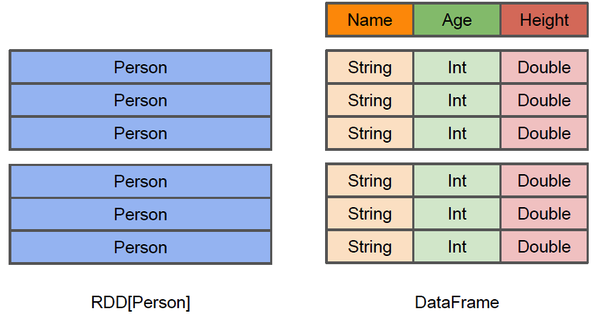
DataFrame 和 RDD 都是可以并行处理的集合,但 DataFrame 更像是一个传统数据库里的表,除了数据之外还可以知道更多信息,比如列名、值、类型。从 API 角度来看 DataFrame 提供了更高级的 API,比 RDD 编程要方便很多,由于 R 语言和 Pandas 也有 DataFrame,这就降低了 Spark 的学习门槛,在编写 Spark 程序时根本不需要关心最后是运行在单机上还是分布式集群上,因为代码都是一样的。
假设 RDD 里面支持的是一个 Person 类型,那么每一条记录都相当于一个 Person,但是 Person 里面到底有什么我们并不知道。DataFrame 存储了各字段的列名、数据类型以及值,有了这些信息,Spark SQL 的查询优化器(Catalyst)在编译的时候就能够做更多的优化。
SQL、DataFrame 和 RDD 运行时性能对比:在大多数情况下 SQL 和 DataFrame 性能要好于 RDD
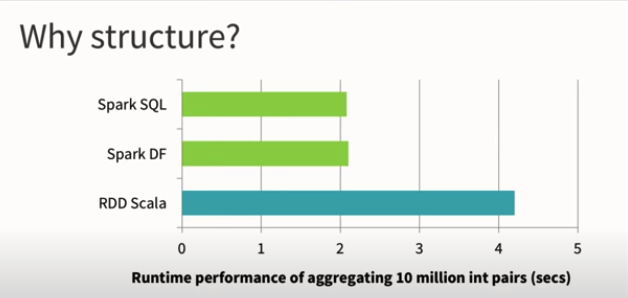
优化器 Catalyst
Spark SQL 的核心是 Catalyst 优化器,一种函数式的可扩展的查询优化器:
- 优化:Catalyst 使查询以更少的资源获取更快的效率;
- 函数式:Catalyst 基于 Scala 的模式匹配和 quasiquotes 机制;
- 可扩展:Catalyst 允许用户扩展优化器;
Catalyst 优化策略
Catalyst 支持两种优化策略:
- 基于规则的优化(Rule-Based Optimization, RBO):使用一组规则来确定如何执行查询;RBO 是一种经验式、启发式优化思路,对于核心优化算子 join 有点力不从心,如两张表执行join 到底使用 BroadcaseHashJoin 还是 sortMergeJoin,目前 Spark SQL 是通过手工设定参数来确定的,如果一个表的数据量小于某个阈值(默认10M)就使用BroadcastHashJoin;
- 基于代价的优化(Cost-Based Optimization, CBO):使用规则生成多个计划,然后选取代价最小的计划执行查询;不同 Physical Plans 输入到代价模型,调整 Join 顺序,减少中间Shuffle 数据集大小,达到最优输出;
Catalyst 工作流程

无论是直接使用 SQL 语句还是使用 DataFrame,都会经过如下环节转换成 DAG 对 RDD 的操作:
- Parser:通过 ANTLR 将 Spark SQL 字符串解析为抽象语法树(Abstract Syntax Tree,AST),即未解析的逻辑计划(Unresolved Logical Plan, ULP);
- Analyzer:通过元数据信息 Catalog 将 ULP 解析为携带 Schema 信息的逻辑计划(Logical Plan, LP);
- RBO:通过 RBO 对 Logical Plan 进行谓词下推、列值裁剪、常量累加等操作,得到优化后的逻辑计划(Optimized logical plan, OLP);
- Planner:将 OLP 转换成多个物理计划(Physical Plan);
- CBO:根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan;
- WholeStageCodegen:生成 Java bytecode 然后在每一台机器上执行,形成 RDD graph/DAG;
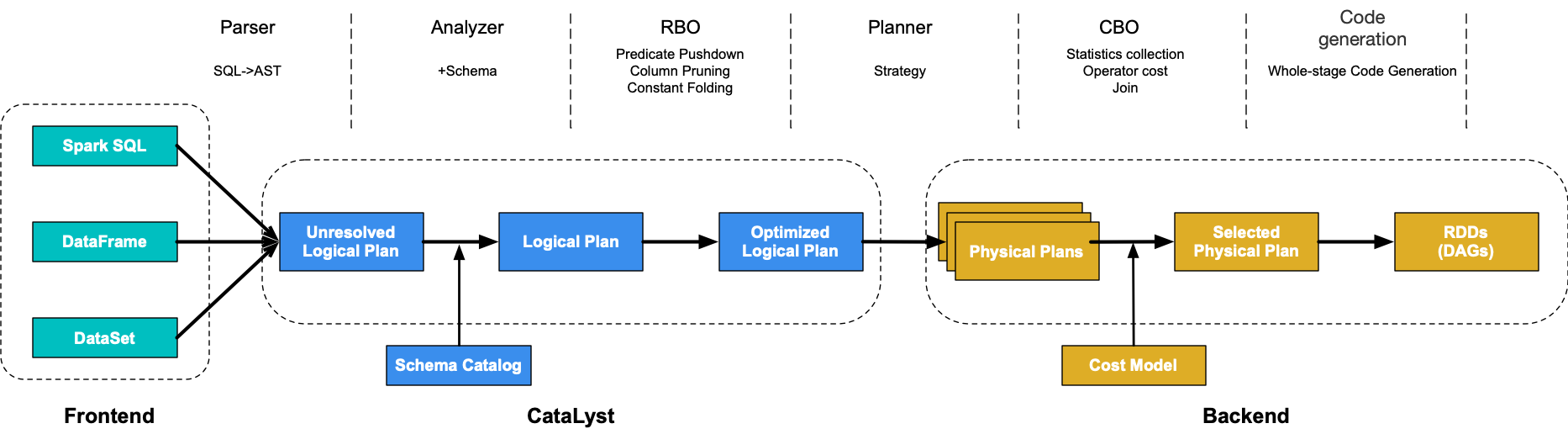
Parser 阶段
Spark2.x SQL 语句的解析采用的是 ANTLR4,ANTLR4 根据语法文件 SqlBase.g4 自动解析生成两个Java类:词法解析器 SqlBaseLexer 和语法解析器 SqlBaseParser。使用这两个解析器将SQL字符串语句解析成了ANTLR4 的 ParseTree 语法树结构。然后在 parsePlan 过程中,使用 AstBuilder.scala 将 ParseTree 转换成catalyst 表达式逻辑计划 Unresolved Logical Plan,ULP。
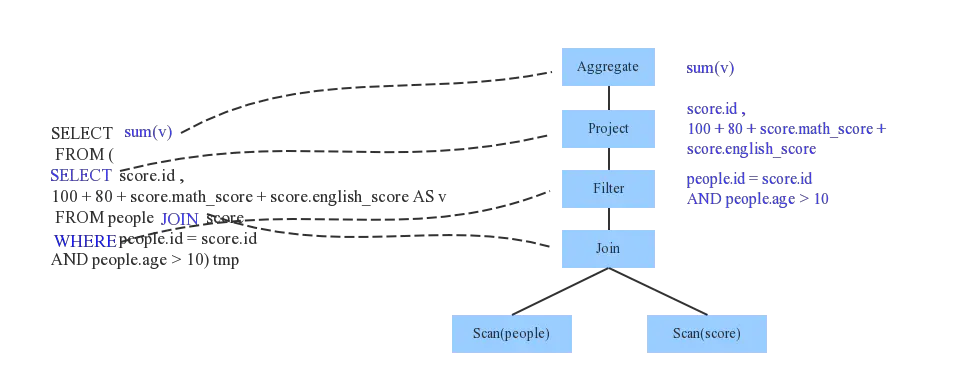
Analyzer 阶段
ULP 还只是一个语法树,系统需要通过元数据信息 Calalog 来获取表的 schema 信息(表名、列名、数据类型)和函数信息(类信息)。Analyzer 会再次遍历整个 AST,对树上的每个节点进行数据类型绑定以及函数绑定,比如people 词素会根据元数据表信息解析为包含 age、id 以及 name 三列的表,people.age会被解析为数据类型为 int 的变量,sum 会被解析为特定的聚合函数,解析后得到 Logical Plan,LP。

RBO 阶段
RBO 的优化策略就是对语法树进行一次遍历,模式匹配能够满足特定规则的节点,再进行相应的等价转换,即将一棵树等价地转换为另一棵树,最终得到优化后的逻辑计划 Optimized logical plan, OLP。
SQL 中经典的常见优化规则有:
- 谓词下推(predicate pushdown):将 Filter 算子尽可能下推,尽可能早地对数据源进行过滤,以减少参与计算的数据量(语法树是从下往上看的)
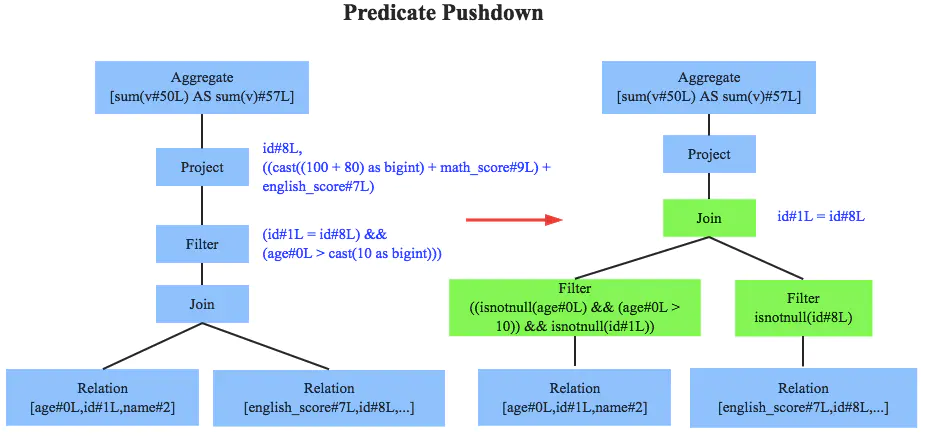
- 列值裁剪(column pruning):剪裁不需要的字段,特别是嵌套里面的不需要字段。如只需people.age,不需要 people.address,那么可以将 address 字段丢弃
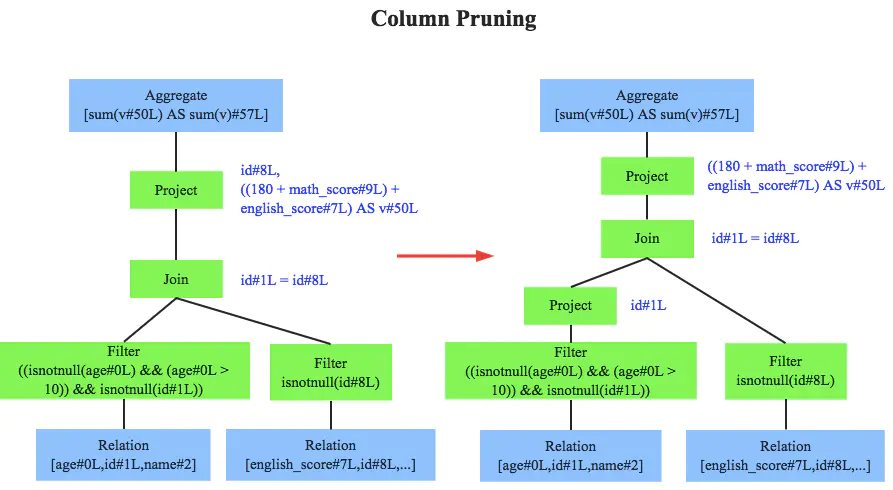
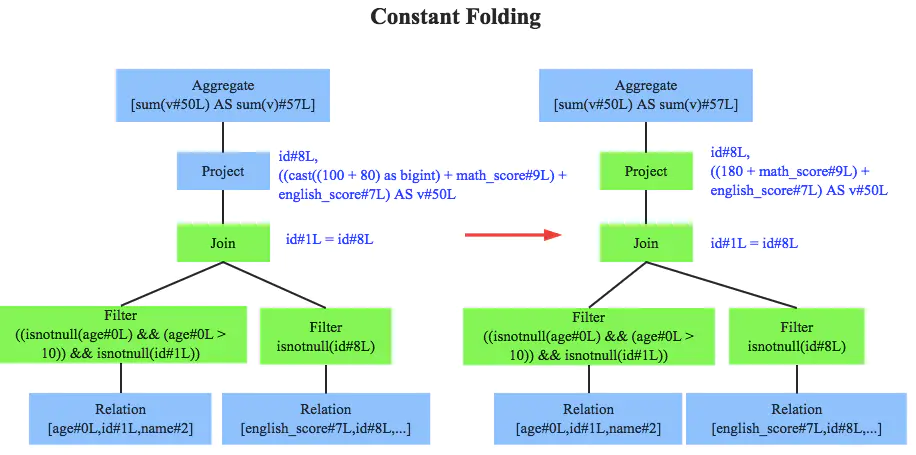
- 常量合并(constant folding):从
100+80优化为180,避免每一条 record 都需要执行一次100+80的操作
Planner 阶段
OLP 只是逻辑上可行,实际上 spark 并不知道如何去执行这个OLP。一个逻辑计划(Logical Plan)经过一系列的策略(Strategy)处理之后,得到多个物理计划(Physical Plans),物理计划在 Spark 是由 SparkPlan 实现的。

CBO 阶段
RBO 属于 LogicalPlan 的优化,所有优化均基于 LogicalPlan 本身的特点,未考虑数据本身的特点,也未考虑算子本身的代价。CBO 充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划,即 SparkPlan。
比如 join 算子,Spark 根据不同场景为该算子制定了不同的算法策略,有 broadcastHashJoin、shuffleHashJoin 以及 sortMergeJoin。CBO 中常见的优化是 join 换位,以便尽量减少中间shuffle 数据集大小,达到最优输出。
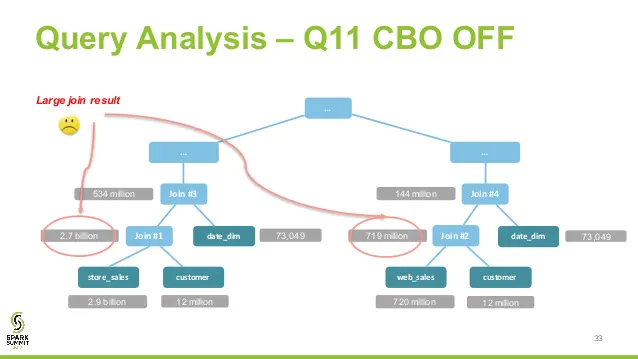
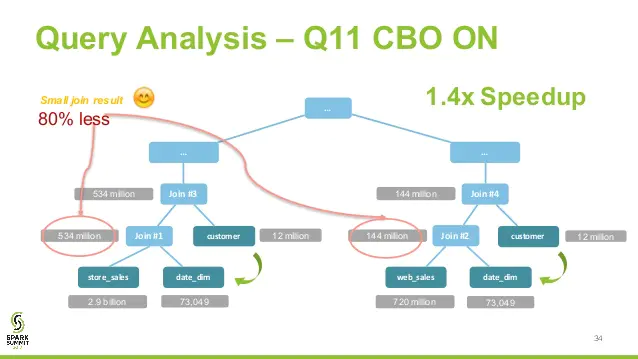
Code Generation 阶段
选出的物理计划还是不能直接交给 Spark 执行,Spark 最后仍然会用一些 Rule 对 SparkPlan 进行处理:
- 全阶段代码生成(Whole-stage Code Generation):用来将多个处理逻辑整合到单个代码模块中。通过引入全阶段代码生成,大大减少了虚函数的调用,减少了 CPU 的调用,使得 SQL 的执行速度有很大提升。
- 代码编译:生成代码之后需要解决的另一个问题是如何将生成的代码进行编译然后加载到同一个 JVM 中去,Spark 引入了 Janino 项目,参见 SPARK-7956。Janino 是一个超级小但又超级快的 Java™ 编译器. 它不仅能像 javac 工具那样将一组源文件编译成字节码文件,还可以对一些 Java 表达式,代码块,类中的文本(class body)或者内存中源文件进行编译,并把编译后的字节码直接加载到同一个 JVM 中运行。Janino 不是一个开发工具, 而是作为运行时的嵌入式编译器,比如作为表达式求值的翻译器或类似于 JSP 的服务端页面引擎,关于 Janino 的更多知识请参见这里。通过引入了 Janino 来编译生成的代码,结果显示 SQL 表达式的编译时间减少到 5ms。需要注意的是,代码生成是在 Driver 端进行的,而代码编译是在 Executor 端进行的。
参考
- 《Spark 权威指南》_online/):正如书名所言,对Spark 各个方面做了权威的介绍,中文版现已出版,网上也有牛人博客的翻译
- Spark 2.2.x 中文文档:官方文档中文版翻译,每一块内容都蜻蜓点水
- Spark By Examples:通过实际例子学习 Spark 的绝佳去处
- org.apache.spark.sql.Dataset:Dataset 对象方法
- org.apache.spark.sql.Dataset.Column:Column 对象方法
- Spark SQL Catalyst优化器
- 一条 SQL 在 Apache Spark 之旅(上)
- 一条 SQL 在 Apache Spark 之旅(中)
- 一条 SQL 在 Apache Spark 之旅(下)
- SparkSql的优化器-Catalyst
- Spark SQL / Catalyst 内部原理 与 RBO
- Spark SQL 性能优化再进一步 CBO 基于代价的优化
- Spark SQL Optimization – Understanding the Catalyst Optimizer
