本文主要讨论 Spark 在执行代码时会发生什么,我们以一种忽略具体实现的方式来讨论这个问题,既不依赖于所使用的集群管理器,也不依赖于正在运行的代码。
Spark 运行时架构
基本组件
Spark 运行时架构包含以下三种基本组件:
- Driver:是 Spark 程序的主控进程,主要负责:
- 创建 Spark 上下文;
- 提交 Spark 作业(job);
- 在各 Executor 进程间分配、协调任务(Task)调度;
- Executor:是执行具体任务的进程,主要负责:
- 执行计算任务(Task);
- 将结果返回给 Driver;
- 为需要持久化的 RDD 提供存储功能;
- 集群管理器:负责维护运行 Spark 程序的机器集群,集群管理器也有自己的 driver(称为主节点 master)和工作者(称为工作节点 worker),但是它们与物理机器而不是进程相关联。下图显示了一个基本的集群设置,左侧机器是群集管理器的 master 节点,右侧机器是集群管理器的 worker 节点,圆圈表示相应进程,目前为止,还没有运行 Spark 应用程序,这些只是来自集群管理器的进程。Spark 目前支持三个集群管理器:一个简单的内置独立集群管理器、Apache Mesos 和 Hadoop Yarn,但是,这个列表将继续增长;
执行模式
执行模式使您能够在运行应用程序时确定上述资源的物理位置,有三种模式可供选择(在下面的部分中,带实心边框的矩形表示 driver 进程,而带虚线边框的矩形表示 executor 进程):
- 集群模式(Cluster mode):集群模式是运行 Spark 应用程序最常见的方式,在集群模式下,用户向集群管理器提交预编译的 JAR、Python 脚本或 R 脚本。然后,除了 executor 之外,集群管理员在集群内的 worker 节点上启动 driver 进程。
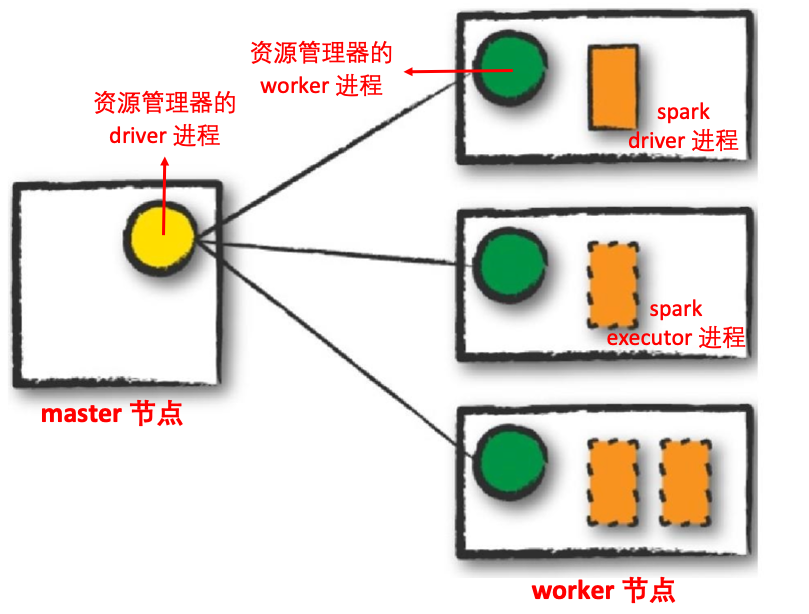
- 客户端模式(Client mode):客户端模式与集群模式几乎相同,只是 Spark driver 程序保留在提交应用程序的客户端上,这意味着客户端负责维护 Spark driver 进程,集群管理器维护 executor 进程。
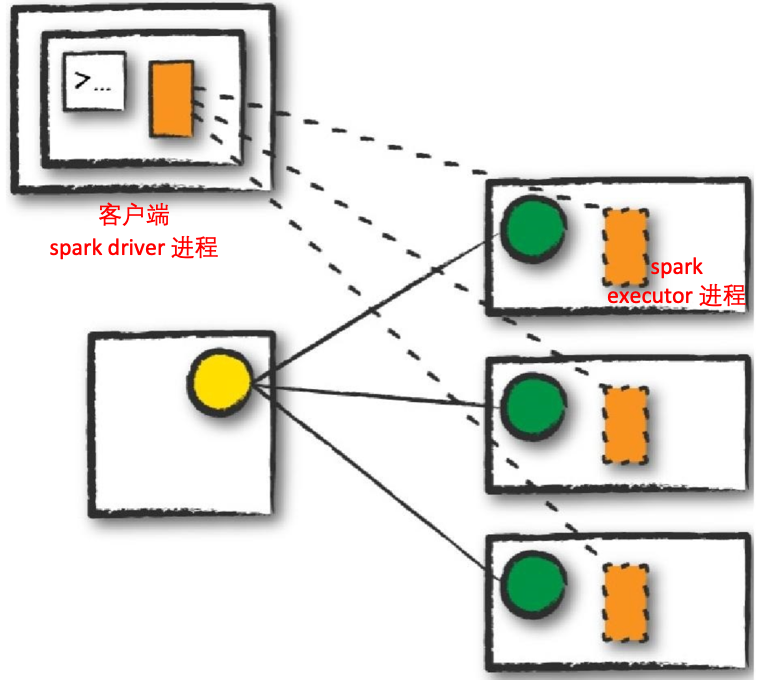
- 本地模式(Local mode):本地模式与前两种模式有很大不同,它在一台机器上运行整个 Spark 应用程序,它通过单个机器上的线程实现并行性。这是学习 Spark、测试应用程序或使用本地开发进行迭代实验的常用方法,但是,我们不建议在运行生产应用程序时使用本地模式。
Spark 程序的生命周期
Spark 外部生命周期
从 Spark 代码外部来看 Spark 应用程序的整个生命周期:
- 客户端请求:
- 第一步是在本地计算机上执行代码(预编译的 JAR),并向集群管理器 master 节点发出请求,为 Spark driver 进程提供资源;
- 集群管理器接受请求,并将 driver 程序放在集群的一个 worker 节点上;
- 提交原始作业的客户端进程退出;
- 启动程序:
- Spark driver 开始运行用户代码,此代码必须包含初始化 Spark 集群的 SparkSession;
- SparkSession 随后将与集群管理器(较暗的线)通信,要求它在集群中启动 Spark executor 进程(较亮的线),执行器(executor)的数量及其相关配置由用户通过原始 Spark-submit 调用中的命令行参数设置;
- 集群管理器通过启动 executor 进行响应,并将有关其位置的相关信息发送到 driver 进程,在所有的东西都连接正确之后,我们就有了一个 Spark 集群;
- 执行:driver 和 executor 之间进行通信,执行代码并移动数据,driver 将任务分配到每个 executor,每个 executor 执行接收的具体任务,并将执行状态以及结果反馈给 driver;
- 完成:Spark 程序完成后,Driver 以成功或失败退出,然后,集群管理器为 driver 关闭该 Spark 集群中的 executor;

Spark 内部生命周期
相比 Spark 的外部生命周期,Spark 内部(用户代码)生命周期更加重要:
- 创建 SparkSession;
- 按照 Action 划分 Job;
- 按照 Shuffle 划分 Stage;
- 按照 Partition 划分 Task;
SparkSession(会话)
任何 Spark 应用程序的第一步都是创建 SparkSession,在许多交互模式中,这是为您完成的,但在应用程序中,您必须手动完成。一些遗留代码可能使用新的 SparkContext 模式。应该避免这样做,因为 SparkSession 上的 builder 方法更能有力地实例化 Spark 和 SQL 上下文,并确保没有上下文冲突,因为可能有多个库试图在同一Spark应用程序中创建会话。
1 | // Creating a SparkSession in Scala |
在进行 SparkSession 之后,您应该能够运行 Spark 代码。通过 SparkSession,您还可以相应地访问所有低阶和遗留上下文和配置。请注意,SparkSession 类只添加在 Spark 2.x 中。您可能会发现,较旧的代码将直接为结构化API创建 SparkContext 和 sqlContext。
Job(作业)—— 划分标准:Action
Spark 代码基本上由转换(transformation)和动作(action)组成,在 Spark 中,所有的 transformation 类型操作都是延迟计算的,Spark 只是记录了将要对数据集进行的操作,只有需要将数据返回到 Driver 程序时(即触发 Action 类型操作),所有已记录的 transformation 才会执行,这被称为“惰性计算”。通常,Spark 会按照动作(action)将 Spark 程序划分为不同的 Job。
transformation 种类繁多,我们只需要记住那些会将数据返回到 Driver 程序的那些操作即可:
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| collect() | 所有元素 | rdd.collect() | {1,2,3,3} |
| count() | 元素个数 | rdd.count() | 4 |
| countByValue() | 各元素在rdd中出现的次数 | rdd.countByValue() | {(1,1),(2,1),(3,2)} |
| take(num) | 从rdd中返回num个元素 | rdd.take(2) | {1,2} |
| top(num) | 从rdd中返回最前面的num个元素 | rdd.top(2) | {3,3} |
| takeOrdered(num)(ordering) | 按提供的顺序,返回最前面的 num 个元素 | rdd.takeOrdered(2)(myOrdering) | {3,3} |
| takeSample(withReplacement,num,[seed]) | 从rdd中返回任意一些元素 | rdd.takeSample(false,1) | 非确定的 |
| reduce(func) | 整合RDD中的所有数据 | rdd.reduce((x,y)=>x+y) | 9 |
| fold(zero)(func) | 和reduce一样,但是需要初始值 | rdd.fold(0)((x,y)=>x+y) | 9 |
| aggregate(zeroValue)(seqOp,combOp) | 和reduce()相似,但是通常返回不同类型的函数 | rdd.aggregate((0,0))((x,y)=>(x,y)=>(x._1+y,x._2+1),(x,y)=>(x._1+y._1,x._2+y._2)) | (9,4) |
| foreach(func) | 对RDd中的每个元素使用给定的元素 | rdd.foreach(func) | 无 |
Stage(阶段)—— 划分标准:Shuffle
Spark 中的阶段(stage)表示可以一起执行以在多台计算机上并行计算相同操作的任务(task)组。一般来说,Spark 会尝试将尽可能多的工作(即工作中尽可能多的转换)打包到同一个阶段(stage),但引擎会在称为洗牌(Shuffle)的操作后启动新的阶段(stage)。
在“Spark 指南:Spark 原理(一)—— Partition 和 Shuffle”一文中我们讲过宽依赖算子会导致 Shuffle,这里重温一下那些会导致 Shuffle 的算子:
- groupByKey、reduceByKey、combineByKey、cogroup、groupWith
- join、leftOuterJoin、rightOuterJoin
- intersection、distinct
- repartition
Shuffle 过程首先会将前置 Stage 的 Map Task 结果写入本地磁盘(Shuffle Write),然后后续 Stage 的 reduce Task 会从磁盘中读取这些文件(Shuffle Read)来执行计算,这有两点好处:
- 将 Shuffle 文件写入磁盘(称为 Shuffle 持久化),使得 Spark 能够在时间上串行地执行不同的 Stage;
- 出现故障时,只需要重启 Reduce Task ,而不用重新运行所有的任务。
Task(任务)划分标准:Partition
每个任务(task)对应于将在单个执行器(executor)上运行的数据块(Partition)和一组转换的组合。Task 只是应用于数据单元(Partition)的计算单位,将数据划分为更多数量的分区意味着可以并行执行更多数据。如果我们的数据集中有一个大分区,我们将有一个任务;如果有1000个小分区,我们将有 1,000 个可以并行执行的任务。
使 Spark 成为“内存计算工具”的一个重要原因是,与之前的工具(如 MapReduce)不同,Spark 在将数据写入内存或磁盘前会尝试执行尽可能多的步骤。Spark 执行的关键优化之一是 pipelining,它发生在 RDD 及以下级别。使用流水线技术,任何可以将数据直接传递给彼此而无需在节点间移动的操作序列,都会被折叠成单个任务阶段,阶段内的所有操作会一起执行。例如,如果您编写一个基于 RDD 的程序,该程序执行一个 map,一个 filter,然后是另一个 map,则这些将导致单阶段任务,这些任务立即读取每个输入记录,将其传递给第一个 map,再将其传递给 filter,并在需要时将其传递给最后一个 map 函数。这种流水线式的计算比在每个步骤之后将中间结果写入内存或磁盘要快得多。
参考
- How Spark Runs on a Cluster Spark_online/)
