分区
分区(Partition)是控制 RDD 在各节点上分布情况的高级特性,RDD 的存储和计算都是基于分区来进行的。为分布式数据集选择正确的分区方式和为本地数据选择合适的数据结构很相似 —— 数据分布都会极其明显地影响程序的性能。有时使用可控的分区方式把常被一起访问的数据放到同一个节点上,可以大大减少应用的通信开销,带来明显的性能提升。
分区的特性
RDD、分区、TASK、节点、核之间的关系:
- 一个 RDD 会被划分为一个或多个分区;
- 这些分区会被保存到多个节点,每个节点可能存储一个或多个分区,但是一个分区只能位于同一个节点,不能跨节点保存,分区是决定 RDD 分布的最小单位;
- RDD 的分区数是可以配置的,默认会等于所有 executor 的核数;
- Spark 会为每个分区分配一个 TASK,每个核一次处理一个 TASK;
默认分区
RDD 创建方式不同,会产生不同的默认分区行为。比如,从 HDFS 中读取文件来创建 RDD 和通过一个 RDD 转换操作生成另一个新的 RDD 的分区行为是不同的。
- 分布式化一个本地数据集:
| 调用 API | 默认分区数 | 分区器类 |
|---|---|---|
sc.parallelize(...) |
sc.defaultParallelism |
无 |
- 从 HDFS 读取数据:
| 调用 API | 默认分区数 | 分区器类 |
|---|---|---|
sc.textFile(...) |
sc.defaultParallelism 和文件 block 数中较大值 |
无 |
- 转换操作:由于 map、flatMap 操作结果可能会改变原 RDD 的 KEY,结果 RDD 会丢失分区器,如果希望继承父 RDD,可以使用 mapValues、flatMapValues,后两者会针对于 (K,V) 形式的类型只对 V 进行操作
| 调用 API | 默认分区数 | 分区器类 |
|---|---|---|
| filter,map,flatMap,distinct | 同父 RDD | filter同父 RDD,其他无分区器 |
| mapValues, flatMapValues | 同父 RDD | 同父 RDD |
| union | union 的两个 RDD 分区数之和 | 无 |
| subtract | 同第一个RDD | 无 |
| cartesian | 两个 RDD 分区数乘积 | 无 |
- 聚合操作:
| 调用 API | 默认分区数 | 分区器类 |
|---|---|---|
| reduceByKey,foldByKey,combineByKey | 同父 RDD | HashPartitioner |
| sortByKey | 同父 RDD | RangePartitioner |
| cogroup,groupByKey,join,leftOuterJoin,rightOuterJoin | 取决于 RDD 的输入属性 | HashPartitioner |
分区器
Partitioner(分区器)定义了 RDD 的分区分布,决定了一个 RDD 可以被分成多少个分区,以及每个分区的数据量有多大,进而决定了每个 Task 将处理哪些数据。一般来说,分区器是针对 key-value 值 RDD 的,并通过对 key 的运算来划分分区,非 key-value 形式的 RDD 无法根据数据特征来进行分区,也就没有设置分区器,此时 Spark 会把数据均匀的分配到执行节点上。
目前的版本提供了三种分区器:
- HashPartitioner(哈希分区器): HashPartitioner 是基于 Java 的
Object.hashCode来实现的分区器,根据Object.hashCode来对 key 进行计算得到一个整数,再通过公式Object.hashCode % numPartitions计算某个 key 该分到哪个分区,当 RDD 没有 Partitioner 时,会把 HashPartitioner 作为默认的 Partitioner; - RangePartitioner(范围分区器): RangePartitioner 将 key 位于相同范围内的记录分配给给定分区,排序需要 RangePartitioner,因为 RangePartitioner 能够确保通过对给定分区内的记录进行排序,最终完成整个RDD的排序;
- 自定义分区器: 通过继承 Partitioner 抽象类,可以定制自己的分区器;
获取分区
在 Scala 和 Java 中,你可以使用 RDD 的 partitioner 属性(Java 中使用 partitioner() 方法)来获取 RDD 的分区方式。它会返回一个 scala.Option 对象,这是 Scala 中用来存放可能存在的对象的容器类。你可以对这个 Option 对象调用 isDefined() 来检查其中是否有值,调用 get() 来获取其中的值。如果存在值的话,这个值会是一个 spark.Partitioner 对象。这本质上是一个告诉我们 RDD 中各个键分别属于哪个分区的函数。
1 | pairs.groupByKey().partitioner.get |
设置分区
有三种方式可以用于设置 RDD 的分区数,但要注意,若改变分区数量或分区器通常会导致 Shuffle 操作,务必在调整分区后进行缓存:
- 调用
partitionBy方法:下面代码,我们自定义了一个分区器,并根据自定义的分区器对 RDD 进行重新分区,需要特别注意的是,在每次调用partitionBy之后,务必对结果进行缓存,否则后续每次惰性执行时都会重新执行分区动作,严重影响程序性能;
1 | import org.apache.spark.Partitioner |
- 通过转换操作返回带有特定分区的 RDD:这部分(读取数据源、转换继承)在上面默认分区器部分已讲过;
- 调用
repartition或coalesec方法:coalesce(numPartitions: Int, shuffle: Boolean = false):对 RDD 进行重分区,使用 HashPartitioner,第一个参数为重分区的数目,第二个为是否进行 shuffle,默认为false(此时是合并分区,父 RDD 和子 RDD 是窄依赖,不会产生 Shuffle);如果重分区的数目大于原来的分区数,那么必须指定 shuffle 参数为 true;repartition(numPartitions: Int, partitionExprs: Column*):repartition 是 coalesce shuffle 参数为 true 的简易实现,返回一个按 partitionExprs 将原 RDD 划分为 numPartitions 个分区的新 RDD,过程中会发生 Shuffle,父 RDD 和子 RDD 之间构成宽依赖;
分区并不是对所有应用都有好处的,如果给定 RDD 只需要被扫描一次,我们完全没有必要对其预先进行分区处理,只有当数据集多次在诸如 JOIN 这种基于键的操作中使用时,分区才会有帮助。
Shuffle
Shuffle 定义
你永远不会调用一个名为 shuffle 的方法,但是有很多方法会导致 shuffle 的发生,比如在 RDD 上调用 groupByKey() 方法时,会返回一个 ShuffledRDD:
1 | val pairs = sc.parallelize(List((1, "one"), (2, "two"), (3, "three"))) |
要执行分布式 groupByKey 操作,我们通常必须在节点之间移动数据,以便数据可以按照它的 KEY 收集到单个机器上:
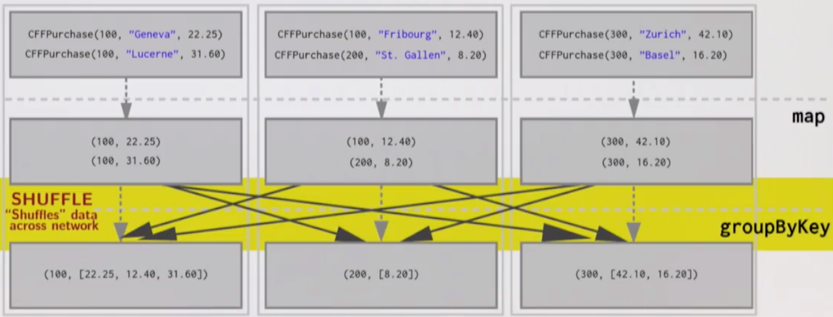
数据通过网络在节点之间移动的过程,称为 Shuffle(洗牌或混洗)。
Shuffle 过程
以 Shuffle 为边界,Spark 将一个 Job 划分为不同的 Stage,这些 Stage 构成了一个大粒度的 DAG。Spark 的 Shuffle 过程分为 Write 和 Read 两个阶段,分属于两个不同的 Stage,前者是 Parent Stage 的最后一步,后者是 Child Stage 的第一步,如下图所示:

Shuffle 过程首先会将前置 Stage 的 Map Task 结果写入本地磁盘(Shuffle Write),然后后续 Stage 的 reduce Task 再从磁盘中读取这些文件(Shuffle Read)来执行计算,这有两点好处:
- 将 Shuffle 文件写入磁盘(称为 Shuffle 持久化),使得 Spark 能够在时间上串行地执行不同的 Stage;
- 出现故障时,只需要重启 Reduce Task ,而不用重新运行所有的任务。
Spark 在 Shuffle 的实现上做了很多优化改进,Spark Shuffle 的演进过程如下(最早实现是 Hash Based Shuffle,2.0 以后就只有 Sort Based Shuffle 了):
- Spark 0.8及以前 Hash Based Shuffle
- Spark 0.8.1 为 Hash Based Shuffle 引入 File Consolidation机制
- Spark 0.9 引入 ExternalAppendOnlyMap
- Spark 1.1 引入 Sort Based Shuffle,但默认仍为Hash Based Shuffle
- Spark 1.2 默认的 Shuffle 方式改为 Sort Based Shuffle
- Spark 1.4 引入 Tungsten-Sort Based Shuffle
- Spark 1.6 Tungsten-sort 并入 Sort Based Shuffle
- Spark 2.0 Hash Based Shuffle 退出历史舞台
Hash Based Shuffle
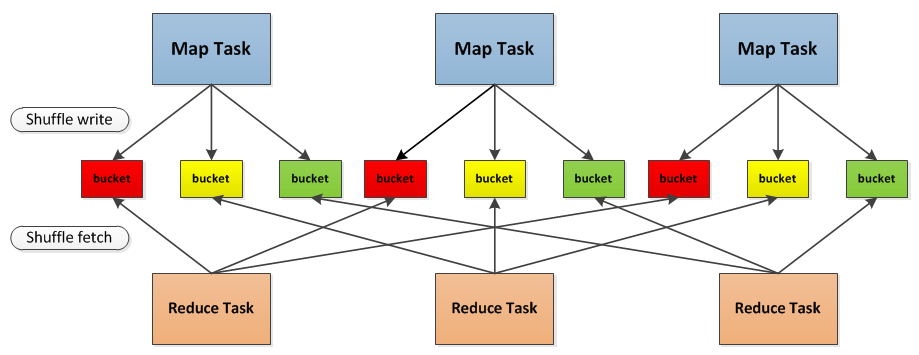
Hash Based Shuffle 的基本流程:
- Shuffle Write: 每个 Map Task 将计算结果数据分成多份(bucket),每一份对应到下游 stage 的每个 Partition 中,写入当前节点的本地磁盘,bucket 的数量就是 $M\times R$,这样会产生大量的小文件,对文件系统压力很大,而且不利于 IO 吞吐量,后面 Spark 做了优化,把在统一 Core 上运行的多个 Mapper 输出合并到同一个文件,这样 bucket 的数量就是 $Cores\times R$;
- Shuffle Read: 每个 Reduce Task 通过网络拉取属于当前任务的 bucket 数据,根据数据的 Key 进行聚合,然后判断是否需要排序,最后生成新的 RDD;
Sort Based Shuffle
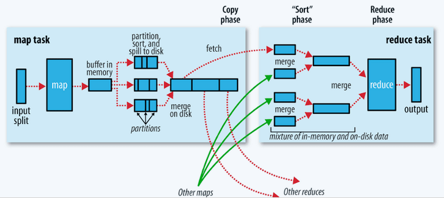
Sort Based Shuffle 的基本流程:
- Shuffle Write: 不会为每个 Reduce Task 生成一个单独的文件,相反会把每个 Map Task 的结果数据写到一个 Data 文件中,并使用 Index 文件存储具体 Map Task 输出数据在同一个 Data 文件中是如何分类的信息;Shuffle Write 过程对每个 Map Task 生成两个文件 —— Data 文件和 Index 文件,因此生成的总文件数为 2M;Shuffle Write 阶段会按照 Reduce Task 的 PartitionId 和记录本身的 Key 进行排序,方便 Reducer 获取数据;
- Shuffle Read: Reduce Task 首先找 Driver 获取每个 Map Task 输出的位置信息,根据位置信息获取 Index 文件,解析 Index 文件获取 Data 文件中属于自己的那部分数据;
Shuffle 规避
和内存计算相比,网络通信和磁盘读写是非常耗时的过程,会严重影响程序执行效率,因此如非必要,应该尽可能避免数据 Shuffle。
宽窄依赖
宽窄依赖定义
为了更好地理解什么时候可能发生 Shuffle,我们需要先看看 RDD 是如何表示的:

RDD 由四部分组成:
- Partitions(分区): 数据的原子性片段,每个节点有一个或多个分区;
- Dependencies(依赖): RDD 转化过程可以表示为一个 DAG,父 RDD 和子 RDD 之间的分区衍生关系;
- Function(函数): 基于父 RDD 的计算;
- Metadata(元数据): 分区 Schema 和数据位置;
事实上,RDD 之间的依赖关系定义了数据何时需要在网络中进行移动,根据父 RDD 和子 RDD 之间的依赖关系,可以将 Transformation 划分为两种:
- Narrow Dependencies(窄依赖): 父 RDD 的每个分区只被子 RDD 中的一个分区依赖,窄依赖不会发生 Shuffle,执行非常块,可以按照 pipeline 进行优化;
- Wide Dependencies(宽依赖): 父 RDD 的每个分区被子 RDD 中的多个分区依赖,宽依赖会导致 Shuffle,执行非常慢,是 Spark 用来划分 Stage 的依据;
宽窄依赖算子
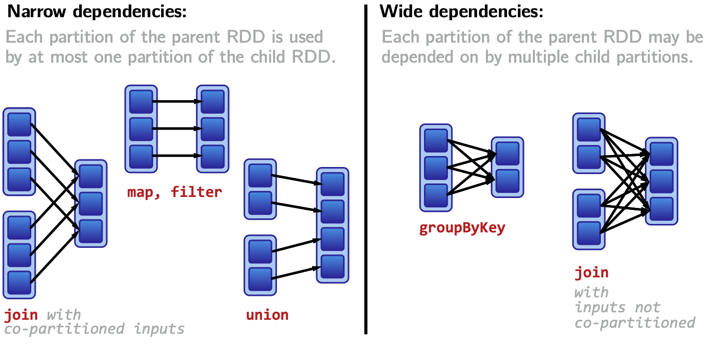
总结 Spark 中常见的宽窄依赖 Transformation:
- 窄依赖:
- map、mapValues、flatMap、mapPartitions
- filter
- union
- co-partitioned join: 两个 RDD 分区方式相同的 JOIN 操作
- coalesce: shuffle=false
- 窄依赖:
- groupByKey、reduceByKey、combineByKey、cogroup、groupWith
- join、leftOuterJoin、rightOuterJoin
- intersection、distinct
- repartition
容错机制
通过追踪分区间的依赖关系可以从血缘图中重新计算丢失的分区数据:
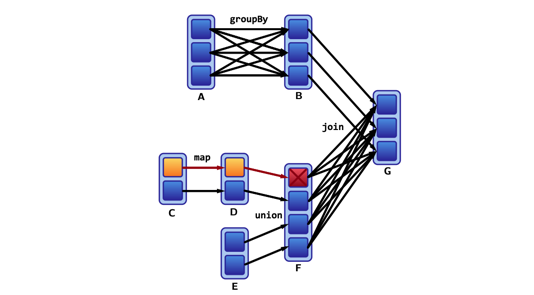
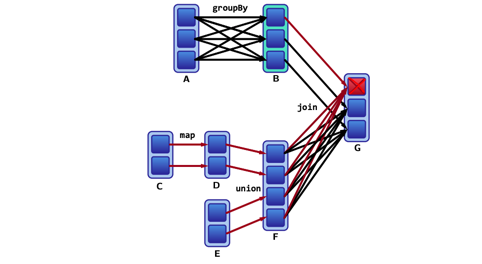
重新计算窄依赖中丢失的分区数据很快,但是要重新计算宽依赖中丢失的分区数据很慢:
使用分区器减少 Shuffle
有一些方法可以让你在使用宽依赖算子的同时尽量避免或减少 shuffle 的发生,其核心思想是通过重分区在集群中合理地组织数据。
分组前预分区
在使用 groupByKey 之类的算子之前先对 RDD 进行预分区(预 Shuffle),之后所有工作都可以在工作节点上的本地分区上完成,无需将数据重新 shuffle 到另一个节点上,在这种情况下,必须移动数据的唯一时间是将最终的 reduce 值从工作节点发送会 Driver 节点:

可以通过 toDebugString 方法查看执行计划:

JOIN 前预分区
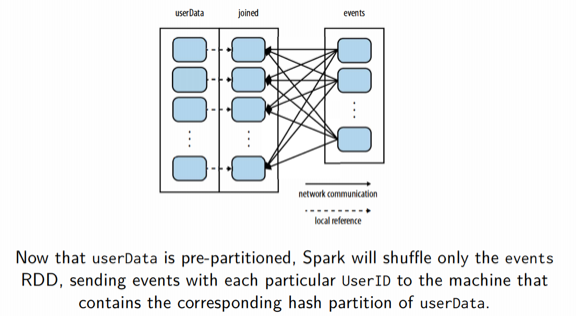
在执行 JOIN 前,使用相同的的分区器对连接的两个 RDD 进行预分区,可以避免 Shuffle,因为需要连接的两个 RDD 的数据已经被重新定位到同一分区中的相同节点上,不需要移动数据。
通过一个实际的例子来看,假设我们想统计有多少用户访问了他们没有订阅的主题,这可以通过用户订阅表和用户点击事件表进行 JOIN 得到:
1 | val sc = new SparkContext( ... ) |
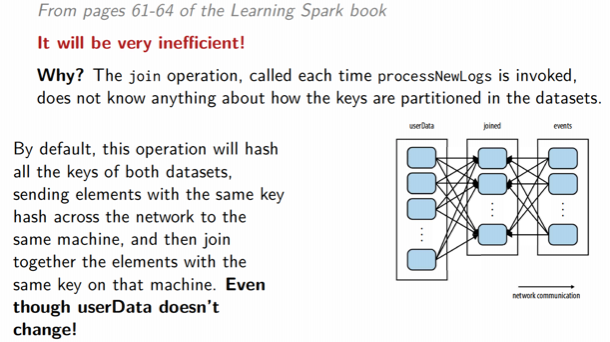
“htt上面的 JOIN 操作会非常耗时,因为 JOIN 操作不知道任何关于数据的分区信息。JOIN 操作默认会 hash 两个数据集所有的 key,并将具有相同 hash 值的记录发送到同一个节点上进行 JOIN。解决办法很简单,就是在 JOIN 之前使用 partitionBy 对大表 RDD 进行重分区:
1 | val userData = sc.sequenceFile[UserID, Userlnfo]("hdfs:// ... ") |
我们在读入 userData 时调用了 partitionBy,Spark 会知道它被 hash 分区了,在后面调用 userData.join(events) 时会利用这一点,按照每个特定的 UserID 将 events RDD shuffle 到包含 userData 对应 hash 分区的节点上。