误差和过拟合
误差分类
- 误差(error):样本的预测输出与真实输出之间的差异。
- 训练误差(training error):也叫经验误差,是指在训练集中样本的预测输出与真实输出之间的差异。
- 验证误差(validation error):是指在验证集中样本的预测输出与真实输出之间的差异
- 泛化误差(generalization error):是指在预测集中样本的预测输出与真实输出之间的差异
在进行模型选择(model selection)时,我们通常希望选取泛化误差最小的模型;但在模型训练(model training)时我们实际能做的是努力使训练误差最小;在模型评估(model validation)时我们通常将验证误差作为泛化误差的近似。
过拟合
由于存在过拟合的风险,训练误差越小并不能保证泛化误差也越小:
- 过拟合(overfitting):因为学习器学习能力太强,误把训练集自身的一些局部特性当做了全局特性,而导致学习器泛化能力降低的现象。
- 欠拟合(underfitting):因为学习器学习能力太弱,连训练集的全局特性都没学好,而导致学习器泛化能力降低的现象。
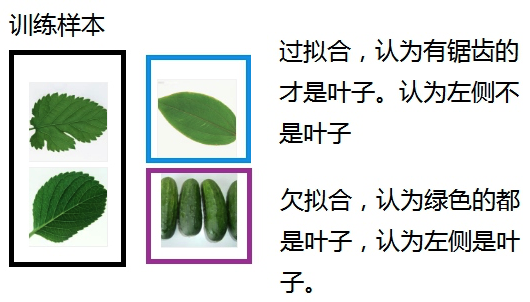
过拟合是机器学习面临的关键障碍,它只能被缓解而无法彻底避免。
模型评估方法
在实验中,我们通常以模型的验证误差作为其泛化误差的近似,来对模型的泛化能力进行评估。假设现在我们有一个包含m个样本的数据集,既要训练又要验证,该怎么做呢?答案是:通过对数据集进行合理划分来产生所需要的训练集S和验证集T,然后用训练集来训练我们的模型,用验证集来评估模型的性能。
验证集的划分准则:
- 分布一致:尽可能保持验证集和训练集数据分布的一致性,否则评估结果将由于训练/验证集分布的差异而产生较大偏差;
- 互斥:尽可能保持验证集和训练集互斥,否则就“泄题”了,评估结果会过于“乐观”;
- 较大规模的训练集:尽可能使训练集的规模接近数据集D的规模,这时的评估结果最为准确;
我们可以按照这三条准则来对数据集进行划分,常用的划分方法有留出法和交叉验证法。
留出法(hold-out)
原理:把数据集D划分为两个互斥子集,分别作为训练集S和验证集T。单次留出法的评估结果往往不够稳定可靠,通常取多次评估结果的平均值作为最终评估结果。
抽样方法:通常采用随机抽样或分层抽样
抽样比例:二八分,训练集8,验证集2
交叉验证法(cross-validation)
- 原理:先把数据集D划分为k个大小相近的互斥子集,然后每次取其中的k-1个子集的并集作为训练集S,取剩下的那个子集作为验证集T,经过k次训练和验证,取k次评估结果的平均值作为最终的评估结果。
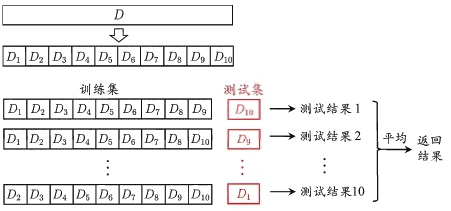
抽样方式:分层采样
k折交叉验证(k-fold cross-validation):k值越大,训练集规模就越接近D的规模,评估结果也越准确,但开销也更大。k最常用的取值是10,称10折交叉验证
留一法:当k=m时,称为留一法。训练集和D接近,评估结果最准确,但开销大。
模型性能指标
性能指标(performance measure):衡量模型泛化能力的评价标准。
回归任务
回归(regression)用于预测结果为数值型的模型,与分类模型相比,回归并没有简单的指标说明预测是否正确,但可以说接近或远离真实值。
残差(residuals):预测值和真实值之间的距离。
均方误差
回归任务中最常用的性能指标是“均方误差”(Mean squared Error,MSE):预测值与真实值之差的平方和的平均值。
- 对于离散分布:
- 对于连续分布:
均方根误差
均方根误差(root-mean-square error,RMSE):
- RMES的优势:结果与参与运算的值有相同单位
- RMES的劣势:RMES的值和问题规模有关,不易于在不同数据集上比较,只限于在同一个项目中进行模型比较
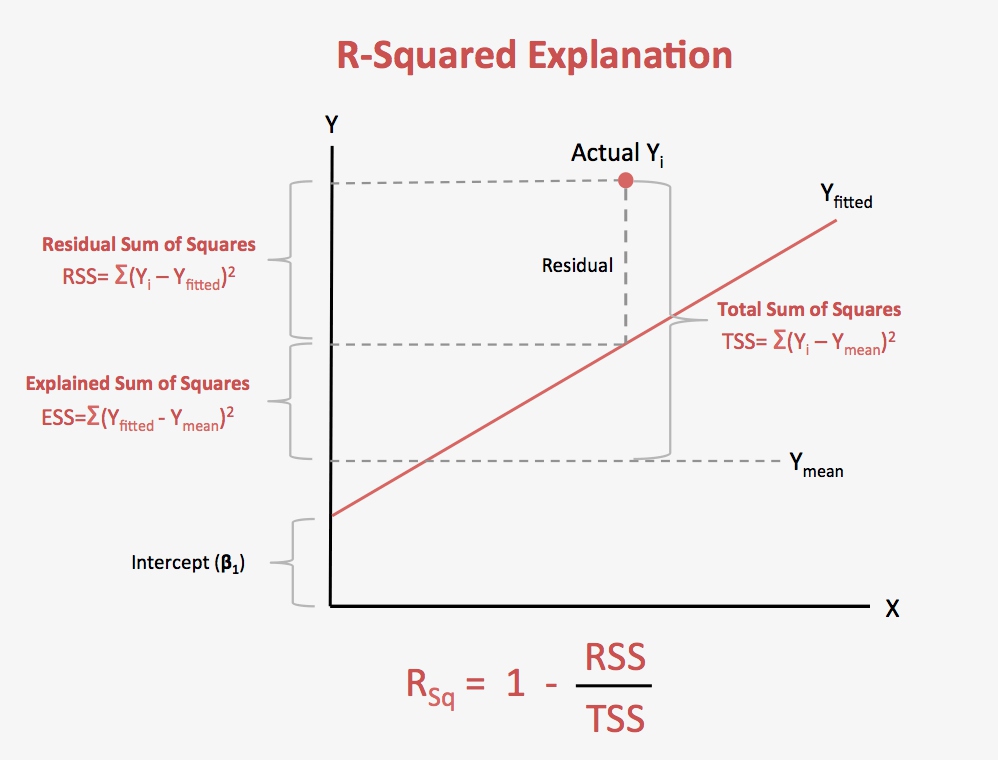
拟合优度
- 拟合优度(Goodness of Fit)是指回归直线对观测值的拟合程度。
- 可决系数$R^{2}$:也称确定系数,是度量拟合优度的统计量
说明:
- SST(total sum of squares):总平方和
- SSE(error sum of squares):残差平方和
- SSR(regression sum of squares):回归平方和
分类任务
错误率和精度
错误率和精度是分类任务中最常用的两种性能度量。对于数据集D,
- 错误率(error rate):错误分类的样本数a与样容量m的比值
- 精度(accuracy):精度=1- 错误率
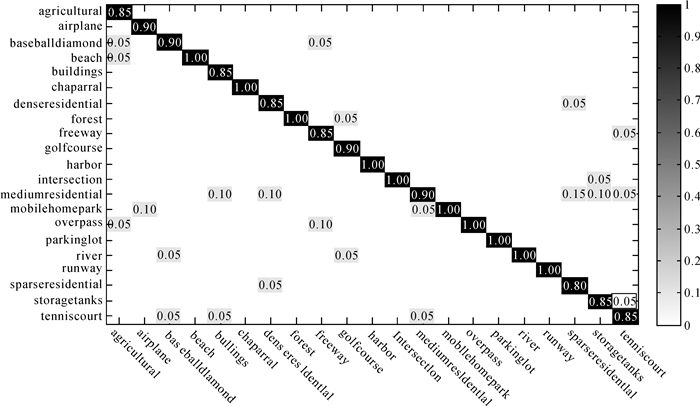
混淆矩阵(confusion matrix)
有时相对于预测精度,我们更关心查准率和查全率(召回率)。对二分类问题,根据样本的真实类别和预测类别的不同组合可以定义出真正例(TP)、假正例(FP)、真负例(TN)、假负例(FN),组合结果的“混淆矩阵”如下:
| 真实\预测 | 正 | 负 |
|---|---|---|
| 正 | TP | FN |
| 负 | FP | TN |
说明:通常混淆矩阵中的元素可以是对应类别的样本数/比例
查准率(precision):预测为正的样本中有多少真实为正。
查全率(recall):真实为正的样本中有多少预测为正。
说明:对于多分类问题,也可以使用混淆矩阵,行列依然表示各个真实类别和预测类别
P-R曲线和F1度量
分类阈值:很多学习器会为每个测试样本产生一个预测值,将其与分类阈值比较,大于阈值则为正类,否则为负类。(魔法旋钮)
查准率和查全率是一对矛盾,如果把阈值设置的较高则查准率较高但查全率较低,反之查准率较低但查全率较高。我们可以通过P-R曲线来直观反映这种关系。
绘制 P-R 曲线:按照预测结果是正例的可能性大小对样本进行排序,然后通过调整阈值(从大到小)逐个将样本作为正例并计算当前的查准率P和查全率R,就得到了P-R曲线。

- 平衡点(Break-Even Point,BEP):P = R 时的取值,BEP较大的模型较优
- F1度量:P和R的调和平均值,越大性能越好
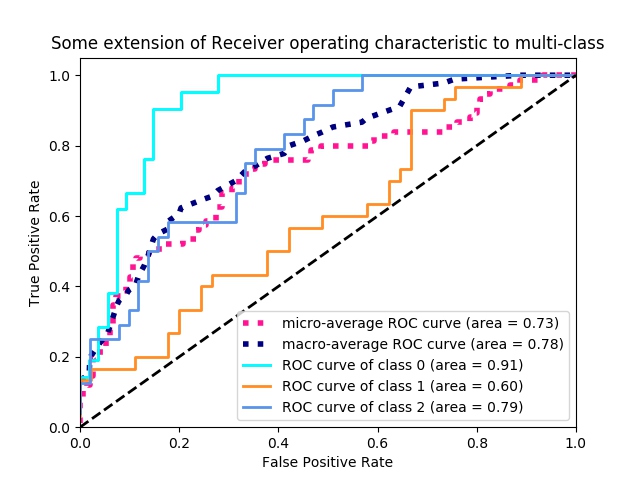
ROC 曲线和 AUC
受试者工作特性(Receiver Operating Characteristic, ROC)与P-R类似,只不过ROC是使用“假正例率”(FPR)和“真正例率”(TPR)来作为曲线的横纵坐标。
- TPR:真实为正的样例中有多少预测为正(同查全率)。
- FPR:真实为假的样例中有多少预测为正
- ROC曲线: 先将样本按预测值进行排序(同P-R曲线),先将阈值设为最大,则所有样本都被预测为负例,TPR = FPR = 0,然后依次减小阈值并重新计算TPR和FPR,当所有样本都被预测为正例时,TPR = FPR = 1。
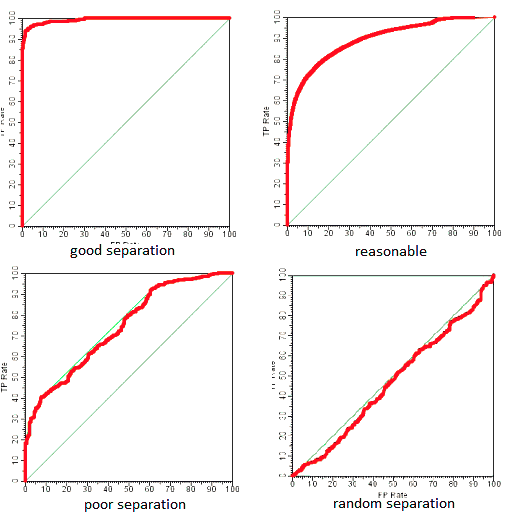
- AUC(Area Under ROC Curve):我们期望较高的真正率和较低的假正率。从图像上看,若一个学习器的ROC曲线被另一个学习器的ROC曲线包裹,则后者性能更好。如果两者交叉,则一般通过ROC曲线下面积AUC来比较,AUC越大性能越好。那么AUC值的含义是什么呢?在论文 Breiman, L., Friedman, J., Olshen, R., Stone, C., Classification and Regression Trees. Wadsworth International Group. 1984.中有这样一段话:”The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example. This is equivalent to the Wilcoxon test of ranks (Hanley and McNeil, 1982). The AUC is also closely related to the Gini coefficient (Breiman et al., 1984), which is twice the area between the diagonal and the ROC curve. Hand and Till (2001) point out that Gini + 1 = 2 AUC.”。简单翻译下:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。另外,AUC与Gini分数有联系,Gini + 1 = 2AUC。AUC 体现出容忍样本倾斜的能力,只反应模型对正负样本排序能力的强弱,而其直观含以上是任意取一个正样本和负样本,正样本的得分大于负样本的概率。
说明:对于多分类问题,我们依然可以对每一种类别分别绘制ROC曲线,将此分类作为正例,将其他分类作为负例来处理。