概率论研究如何量化和计算不确定性,而决策论则研究如何在不确定性中做出最优决策,决策论研究的问题一般可分为两个阶段:
- 推断阶段(inference stage):确定联合概率分布$p(x,y)$或后验概率分布$p(y\mid x)$;虽然联合概率分布能够给出问题完整的概率描述,但并不是必要的;
- 决策阶段(decision stage):在给定概率分布的前提下,进行最优决策;一旦推断问题解决了决策问题就会变得非常简单,甚至不值一提;
我们可以通过概率论中的贝叶斯定理进行决策:
期望损失最小化
损失函数(loss function):是对于所有可能的决策可能产生的损失的一种整体的度量,通常又称代价函数(cost function),记做$L(y,\hat{y})$,其中y是实际值,$\hat{y}$是模型预测值。我们的目标是最小化整体的损失,有些学者不考虑损失函数,而是考虑效用函数(utility function),目标是最大化效用函数,如果让损失函数等于效用函数的相反数的话,这两个概念是等价的。
期望损失最小化原则:在进行决策时通常希望决策所带来的期望损失达到最小。
分类问题
损失矩阵
通常用损失矩阵来描述k分类问题的损失函数:
其中$L_{i,j}$表示将实际为i类的样本预测为j类所带来的损失,对于0-1损失有:
通常我们可以为不同情形赋予不同的损失值,比如在疾病预测时,将正常人预测为病人损失通常较小,而将病人预测为正常损失通常较大。
分类问题描述
分类问题的目标就是要找到某种规则,将输入空间切分为不同的决策区域$R_k$,并将决策区域$R_k$中的所有点都划分到类别$c_k$,使得期望损失达到最小。即:
其中:
对于给定的x,目标就变成了:
对于0-1损失函数:
即,0-1损失下的期望风险最小化等价于最大后验概率策略。
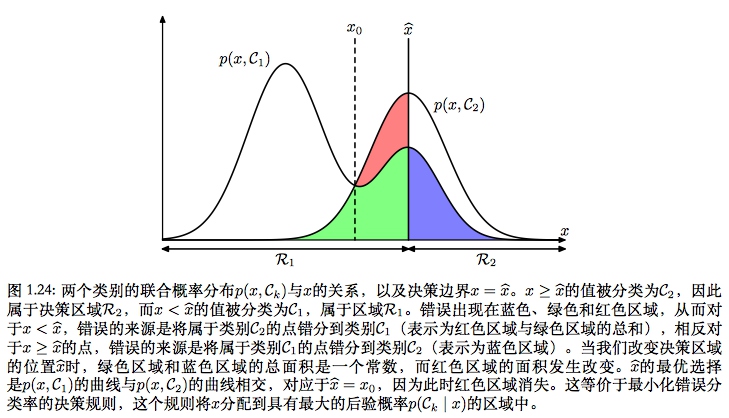
拒绝选项
拒绝选项:当不同类别的联合概率相差不大时,类别的归属相对不稳定,在这种情况下避免做出自动化决策,而将决策权留给人类专家,能够降低模型的分类错误率。
具体地,可以通过引入一个决策阈值$\theta$,拒绝最大后验概率小于$\theta$的那些输入。
回归问题
闵可夫斯基损失函数
闵可夫斯基损失函数是平方损失的一种推广:
- y:输入x对应的真实标签;
- y(x):输入x对应的预测值;
问题描述
回归问题的目标就是对于每个输入x找到一个估计值$y(x)$,使得期望损失最小。
以平方误差为例:
两侧对x求导得:
即,最小化期望平方损失的回归函数由条件均值给出,值得说明的是当q=1时得到的是条件中位数,当$q\rightarrow 0$时得到的是条件众数。
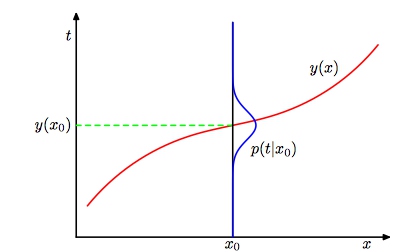
期望平方损失下的偏差-方差分解:其中的交叉项对dy积分可消去
- 第一项表示预测值与条件均值的偏差:当$y(x)=\mathbb{E}(y\mid x)$时,取得最小值;
- 第二项表示条件均值的方差:表示目标数据内在的变化性,可以被看做是噪声,因为与y(x)无关,它表示损失函数的不可减少的最小值;
解决决策问题的三种方法
三种方法按照复杂度降低的顺序给出:
- 生成式模型(generative model):首先解决确定联合概率分布$p(x,y)$的推断问题,然后通过贝叶斯定理求出后验概率分布$p(y\mid x)$,最后基于后验概率分布使用上述方法进行决策;这种方法可以人工生成出输入空间的数据点,故称生成式模型;
- 判别式模型(discriminative model):首先解决确定后验概率分布的推断问题,再基于后验概率分布使用上述方法进行决策;
- 判别函数:与上述两种概率模型不同,该方法将推断阶段和决策阶段结合到同一个过程,直接从训练数据中寻找一个分类/回归函数y(x);
到某个函数$f(x)$,然后将每个输入x直接映射为标签;
三种方法对比:
- 生成式模型:需要求解的东西最多,能够完整描述概率分布,但需要更多数据,也会浪费计算资源;
- 判别式模型:只需求出后验概率,有很多理由需要计算后验概率:
- 最小期望风险:当损失矩阵发生变化时,如果已知后验概率分布,则只需做少量改动即可;
- 拒绝选项:方便设置阈值;
- 补偿类先验概率:对样本不均衡重采样后得到的后验概率分布不能作为真实数据的分布,需要乘以原始数据中的先验概率再除以平衡后的数据中的先验概率,最后再进行归一化;
- 判别函数:模型简单,但无法得到后验概率分布;
参考
- 模式识别与机器学习.Bishop
