理论篇
二分查找(binary search)又称折半查找(half-interval search),用于在有序数组中以 $O(lgn)$ 的时间复杂度快速查找元素。
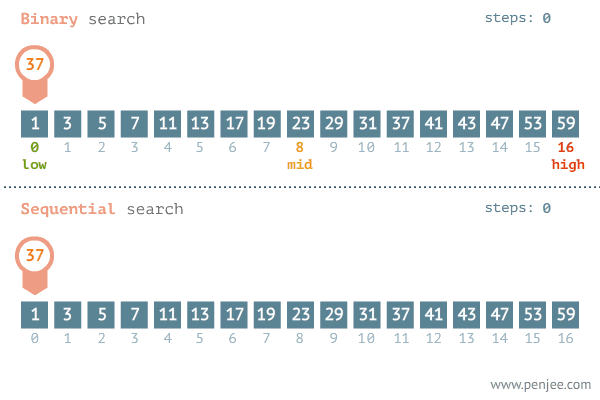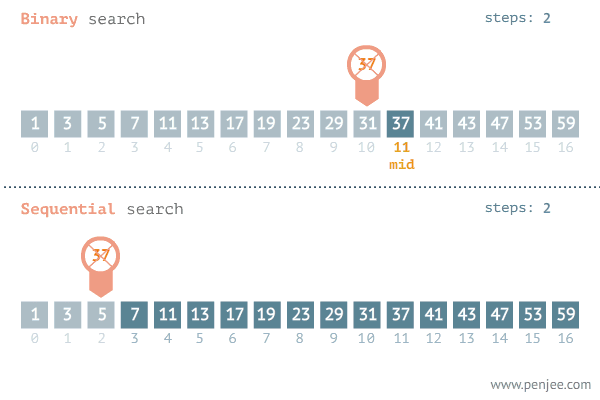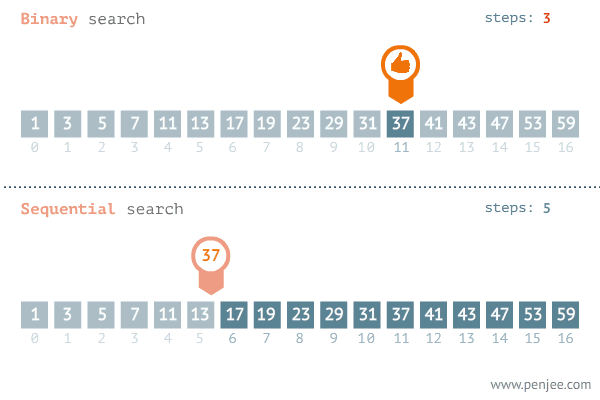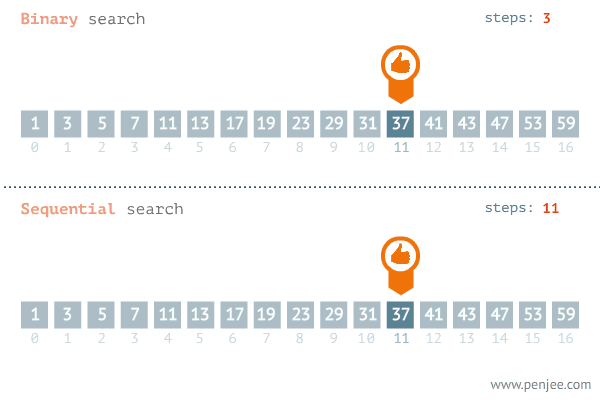
问题定义
二分查找算法所适用问题的形式化定义:在递增函数$f(x), x \in [l,r]$中, 由函数值y反向求取x。
- 递增函数 $f(x)$:$f(x)$ 表示由x计算y的一种函数映射,可以是非严格递增函数;
- x的定义域:x 的定义域标识初始化查找窗口;
- 问题变形:该问题常常演化为寻找第一个 $f(x)\geqslant y$ 的x,或者寻找第一个 $f(x)> y$ 的x;
1 | # 可将bisect统一理解为返回插入后的位置; |
一般原理
二分查找算法的一般框架:
- 初始化查找窗口:使用位置变量来表示当前查找窗口范围,可以使用闭区间表示$[l,r]$或开区间表示$[l,r)$
- 如果查找窗口不为空则循环以下过程:
- 在查找窗口内选取一个元素作为枢轴点,与目标值进行比较
- 如果目标值等于枢轴值,则返回枢轴点下标
- 如果目标值大于数轴值,则在枢轴点右侧窗口继续查找
- 如果目标值小于枢轴值,则在枢轴点左侧窗口继续查找
- 如果窗口为空仍未找到目标值,则返回目标值应插入位置的下标
说明:
- 查找区间表示:既可以使用闭区间也可以使用开区间,在代码实现上注意保证循环不变性以及最终返回值的含义;
- 枢轴值的选择:枢轴点原则上可以选取窗口内的任意元素,对枢轴值的不同选择可能会影响最终二分查找的效率;
代码实现
普通二分查找
闭区间二分查找
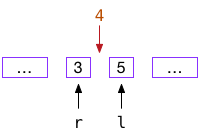
闭区间+下中位数是折半查找最清晰简便的实现,建议作为一般模板:
- 使用闭区间来初始化查找窗口:l=0,r=n-1,[l,r]表示初始化窗口;
- 如果窗口不为空则循环以下过程:窗口不为空即$l\leqslant r$
- 下中位数作为枢轴点:下中位数对应$ \frac{l+r}{2} $位置,上中位数对应$\frac{l+r+1}{2}$位置
- 如果目标值等于枢轴值,则返回数轴值下标
- 如果目标值大于数轴值,则在枢轴点右侧窗口继续查找
- 如果目标值小于枢轴值,则在枢轴点左侧窗口继续查找
- 如果未找到目标值,循环退出时l=r+1,目标值一定处于l和r之间;
1 | # 闭区间写法:用[l,r]代表当前查找范围 |
半开区间二分查找
对窗口的描述方式变了,窗口初始化、退出条件都要做出相应修改,建议只作为参考。
1 | # 开区间写法:用[l,r)代表当前查找范围 |
结论:考虑思路的清晰性和结果的统一性,建议使用闭区间写法,本文以下讨论都是基于二分查找的闭区间写法。
含重复元素的二分查找
当数组中含有重复元素时,如果只需要返回任意一个与目标值相同的元素的下标,则上述代码无需变动,但如果需要查找目标值在数组中第一次/最后一次出现的位置,则需要对以上代码稍加改变即可。
接下来以“LeetCode 34. 在排序数组中查找元素的第一个和最后一个位置”为例,讨论两种方式。
等于作为小于/大于
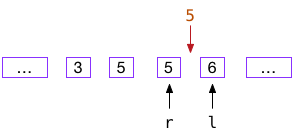
1、如果要寻找target第一次出现的位置,可以假装寻找$target-\varepsilon$,$\varepsilon$是一个大于0的很小的值,实际操作时可以把target==nums[mid]看做是小于,那么最终得到的l,r有以下关系,l=r+1
- 如果数组中存在目标值,nums[l]就是第一个等于target的元素;
- 如果数组中不存在目标值,nums[l]就是第一个大于target的元素;

2、如果要寻找target最后一次出现的位置,可以假装寻找$target+\varepsilon$,$\varepsilon$是一个大于0的很小的值,实际操作时可以把target==nums[mid]看做是大于,那么最终得到的l,r有以下关系,l=r+1
- 如果数组中存在目标值,nums[r]就是最后一个等于target的元素;
- 如果数组中不存在目标值,nums[r]就是最后一个小于target的元素;
1 | def searchRange(self, nums, target): |
记录上一次成功位置
另一种方法对普通的二分查找的修改更少,只需要记录上次找到的位置,然后如果要找第一个就继续在左半部分找,如果要找最后一个就继续在右半部分继续找。
1 | # 返回key在nums中第一次和最后一次出现的位置[L,R],如果不存在则返回[-1,-1] |
- 分析:
- 最坏时间复杂度:O(lgn)
- ASL ≈ lg(n+1)-1
二分查找的改进
折半查找每次选取中间元素作为枢轴点,插值查找和斐波那契查找通过改变枢轴点的选取方式对折半查找进行了改进。插值查找每次以插值的方式确定枢轴点,适合于元素关键字分布比较均匀的情况,斐波那契查找则是每次选取黄金分割点作为枢轴点。
插值查找
插值查找每次通过插值的方式来选取枢轴点:
插值查找:
mid = l + (r-l)*(key-L[l])/(L[r]-L[l]),其中L[r] != L[l],L[l] <= key <= L[r]1
2
3
4
5
6
7
8
9
10
11
12
13def insertion_search(L,key):
l,r = 0,len(L)-1
while l <= r:
if key > L[r] or key < L[l]:return -1
if L[r] == L[l]:return r
mid = int(l + (r-l)*(key-L[l])/float((L[r]-L[l])))
if key == L[mid]:
return mid
elif key > L[mid]:
l = mid + 1
else:
r = mid - 1
return -1分析:平均时间复杂度O(loglogN),当关键字在数据集中分布较均匀时性能最好,当分布不均时可能比折半要差
斐波那契查找
- 找到大于F[k]-1 >= n的第一个k,在列表后面补充最后一个元素,使列表长度恰好为F[k]-1
- 选取mid = l+F[k-2]-1,恰好将列表分为左右F[k-2]-1和F[k-1]-1个元素
- 接下来和折半查找过程一致,只需判断相等时mid是否大于n-1
1 | F = [0,1] |
- 分析:同样,斐波那契查找的时间复杂度还是O(log2n),但是与折半查找相比,斐波那契查找的优点是它只涉及加法和减法运算,而不用除法,而除法比加减法要占用更多的时间,因此,斐波那契查找的运行时间理论上比折半查找小,但是还是得视具体情况而定
应用篇
应用二分查找算法解决实际问题的关键在于将问题抽象为“递增函数由y求x的问题”。具体地,应用二分查找算法分三步:
- 定义递增函数$f(x)$:明确递增函数的含义,x一般表示问题待求的值(如下标),f(x)一般表示条件取值(如数组元素);实现$f(x)$的计算过程(如数组索引取值);值得说明的是,在定义出$f(x)$之后,并不需要将x所有定义域上的函数值全部求出,只需要计算每次选取的数轴点处的函数值即可(现取现用);
- 确定$f(x)=k$时的定义域:一般可以通过函数值确定x的一个大致取值范围,该范围不必精确,只需保证包含x的确切解即可;
- 问题转化:将原始问题转化为在$f(x)$序列中寻找第一个大于(第一个大于等于、最后一个小于、最后一个小于等于)y的x的问题;
问题转化后即可套用二分查找的一般框架进行求解。
二分查找一般用于求解以下问题:
- 递增函数中查找某个值的问题:值作为y,下标作为x
- 递增函数中查找第k小问题:名次作为y,值作为x
数学问题
[LeetCode 69] 求x的平方根
- 问题:实现 int sqrt(int x) 函数
- 思路:f(x)=x**2,$x \in [1,x]$,在f(x)序列中查找最后一个<=target的x
- 实现:
1 | def mySqrt(self, x): |
[LeetCode 367] 有效的完全平方数
- 问题:给定一个正整数 num,编写一个函数,如果 num 是一个完全平方数,则返回 True,否则返回 False
- 思路:单调函数f(i) = i*i,f(x)=val,x in [0,num],是否能找到
- 代码:
1 | def isPerfectSquare(self, num): |
[LeetCode 668] 乘法表中第k小的数
- 问题:给定高度m 、宽度n 的一张 m * n的乘法表,以及正整数k,你需要返回表中第k 小的数字
1 | 输入: m = 3, n = 3, k = 5 |
- 思路:二分查找。令f(x)表示乘法表中小于等于x的数字个数
- 单调增函数f(x):sum(min(m, x / i) for i in range(1, n + 1))
- f(x)=k时,x取值范围[1,k]问题转化为在f(x)中查找第一个大于等于k的x
- 代码:
1 | def findKthNumber(self, m, n, k): |
[LeetCode 275] H指数 II
- 问题:给定一位研究者论文被引用次数的数组(被引用次数是非负整数),数组已经按照升序排列。编写一个方法,计算出研究者的 h 指数。h 指数的定义: “一位有 h 指数的学者,代表他(她)的 N 篇论文中至多有 h 篇论文,分别被引用了至少 h 次,其余的 N - h 篇论文每篇被引用次数不多于 h 次。”
1 | 输入: citations = [0,1,3,5,6] |
思路:定义设f(h)表示”h-引用次数第h大的文章的引用次数”,h取值范围为[1,n],f(h)是非降函数,问题转化为寻找最后一个h使得f(h)<=0,如果没有则返回0
代码:
1 | def hIndex(self, citations): |
[LeetCode 483] 最小好进制
- 问题:对于给定的整数 n, 如果n的k(k>=2)进制数的所有数位全为1,则称 k(k>=2)是 n 的一个好进制。以字符串的形式给出 n, 以字符串的形式返回 n 的最小好进制。
- 思路:
1 | 1+k+k^2+...k^r=(1-k^(r+1))/(1-k)=n |
- 代码:
1 | def smallestGoodBase(self, n): |
[LeetCode 878] 第 N 个神奇数字
- 问题:如果正整数可以被 A 或 B 整除,那么它是神奇的。返回第 N 个神奇数字。由于答案可能非常大,返回它模 10^9 + 7 的结果
1 | 输入:N = 1, A = 2, B = 3 |
- 思路:
1 | 二分查找,设f(x)表示<=x的正整数中有多少个神奇数字 |
- 代码:
1 | def nthMagicalNumber(self, N, A, B): |
[LeetCode 793] 阶乘函数后K个零
- 问题:f(x) 是 x! 末尾是0的数量。(回想一下 x! = 1 2 3 … x,且0! = 1)找出多少个非负整数x ,有 f(x) = K 的性质。
1 | 示例 1: |
- 思路:
1 | n!后缀0的个数K,等于不大于n的所有乘数中,因子5的个数: |
- 代码:
1 | def preimageSizeFZF(self, K): |
[LeetCode 4] 两个排序数组的中位数
- 问题:给定两个大小为 m 和 n 的有序数组 nums1 和 nums2 。请找出这两个有序数组的中位数。要求算法的时间复杂度为 O(log (m+n)) 。你可以假设 nums1 和 nums2 不同时为空。
1 | 示例 1: |
- 思路:对齐+二分查找
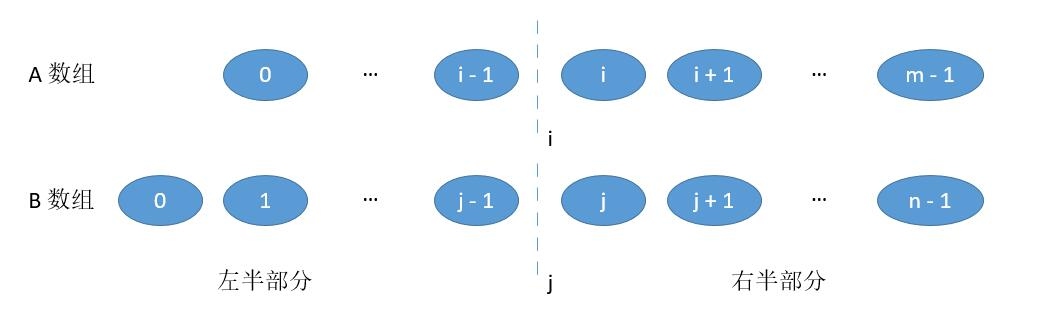
1 | 将A、B数组(m<=n)在i、j位置对齐,如果对齐位置满足以下两个条件: |
- 代码:
1 | def findMedianSortedArrays(self, nums1, nums2): |
- 分析:
- 时间复杂度:我们对较短的数组进行了二分查找,所以时间复杂度是 O(log(min(m,n)))
- 空间复杂度:只有一些固定的变量,和数组长度无关,所以空间复杂度是 O ( 1 )
树
[LeetCode 230] 二叉搜索树中第K小的元素
- 问题:如题
- 思路:统计左子树节点数,如果==k-1则返回根节点,如果>k-1则在左子树中差汇总啊第K小,否则再右子树中查找k-left-1小;
- 代码:
1 | def kthSmallest(self, root, k): |
[LeetCode 222] 完全二叉树的节点个数
- 问题:给出一个完全二叉树,求出该树的节点个数
- 思路:
- 如果左右子树高度相同,那么左子树节点数为2^h-1,h为左子树高度,右子树为一个完全二叉树
- 如果左右子树高度不同,那么右子树节点数为2^h-1,h为右子树高度,左子树为一个完全二叉树
- 代码:
1 | def countNodes(self, root): |
二维矩阵
[LeetCode 74] 二维矩阵中的二分查找
- 问题:编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:每行中的整数从左到右按升序排列;每行的第一个整数大于前一行的最后一个整数。
1 | 输入: |
- 思路:两次二分查找,现在首列进行二分查找,找到则返回,找不到就返回较小的行号,再在所在行进行二分查找,找到就返回,找不到就返回False;
- 代码:
1 | def searchMatrix(self, matrix, target): |
[LeetCode 240] 二维矩阵中的二分查找II
- 问题:
1 | 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target。该矩阵具有以下特性: |
- 思路:取左下角元素为枢轴值,比它大就把规模缩减到右侧,比它小就把规模缩减到上面。O(m+n)
1 | def searchMatrix(self, matrix, target): |
[LeetCode 378] 有序矩阵中第K小的元素
- 问题:给定一个 n x n 矩阵,其中每行和每列元素均按升序排序,找到矩阵中第k小的元素
- 思路:
1 | 思路:二分查找是用于“在递增函数中由y求x的算法”,二分查找用于实际问题的精髓在于将原始问题转化为这在递增函数中由y求x的问题,然后定义递增函数的三要素:定义域、值域、映射;具体的,需要定义函数f(x),定义域[l,r],目标值target |
- 代码:
1 | def kthSmallest(self, matrix, k): |
旋转数组
[LeetCode 153]查找旋转数组中的最小值
- 问题:假设按照升序排序的数组在预先未知的某个点上进行了旋转,假设不含重复元素,请找出其中最小的元素。
1 | 输入: [3,4,5,1,2] |
- 思路:中值和右边界比较,l==r时退出循环;如果中间的值大于右侧的值,说明最小值肯定在mid右侧,否则最小值肯定在mid或mid左侧。
- 代码:
1 | def findMin(self, nums): |
- 分析:时间复杂度为O(lgn)
[LeetCode 154]查找含重复元素的旋转数组中的最小值
- 问题:同153,但是数组中可能含有重复元素
- 思路:中值与右边界比较,l==r时退出循环(l<r时mid<r);如果中值大于右边界,说明最小值在mid右侧,如果中值小于右边界说明最小值在mid或mid左侧,如果中值等于右边界说明最小值在r左侧;
- 代码:
1 | def findMin(self, nums): |
- 分析:最坏时间复杂度为O(n),平均O(lgn)
动态规划
[LeetCode 887] 鸡蛋掉落
- 问题:
1 | 你将获得 K 个鸡蛋,并可以使用一栋从 1 到 N 共有 N 层楼的建筑。 |
- 思路:
1 | 理解题意:用[0,0,...,1,1,1]表示每层楼的结果,0表示不碎,1表示碎,任务是在与1的比较次数<=K的前提下,最少比较几次才能找到最后一个0的位置。 |
- 代码:
1 | def superEggDrop(self, K, N): |
[LeetCode 354] 俄罗斯套娃信封问题
- 问题:给定一些标记了宽度和高度的信封,宽度和高度以整数对形式 (w, h) 出现。当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。请计算最多能有多少个信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
1 | 输入: envelopes = [[5,4],[6,4],[6,7],[2,3]] |
- 思路:
1 | 排序后变成求最长递增子序列问题 |
- 代码:
1 | def maxEnvelopes(self, envelopes): |
[LeetCode 410] 分割数组的最大值
- 问题:给定一个非负整数数组和一个整数 m,你需要将这个数组分成 m 个非空的连续子数组。设计一个算法使得这 m 个子数组各自和的最大值最小。
1 | 输入: |
- 思路:
1 | 思路1:动态规划,超时。令dp[i][m]表示以i为结尾(不含i),分为m段,各段最大值的最小值;有: |
- 代码:
1 | def splitArray(self, nums, m): |
[LeetCode 719] 找出第 k 小的距离对(至尊二分查找)
- 问题:
1 |
|
思路:二分查找+含重复元素的二分查找。令f(x)表示距离小于等于x的数对个数,观察到f(x)是单调增(含重复元素)的函数,寻找数对之间第k小的距离,即是寻找x使得f(x-1)<k<=f(x),这样的问题可以通过二分查找求解;计算f(x)时可以先对nums进行排序,f(x)=sum(i - bisect.bisect_left(nums, num - mid, 0, i) for i, num in enumerate(nums))
代码:
1 | def smallestDistancePair(self, nums, k): |
其他二分查找问题
[LeetCode 852] 山脉数组的峰顶索引
- 问题:
1 | 我们把符合下列属性的数组 A 称作山脉: |
- 思路:如果A[mid] < A[mid+1],说明山峰在mid右侧,否则说明山峰在mid或mid左侧;
- 代码:
1 | def peakIndexInMountainArray(self, A): |
[LeetCode 875] 爱吃香蕉的珂珂
- 问题:
1 | 珂珂喜欢吃香蕉。这里有 N 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 H 小时后回来。 |
- 思路:
1 | 1. f(x)表示速度为x时需要多少个小时吃完,f(x) |
- 代码:
1 | def minEatingSpeed(self, piles, H): |
[360 笔试]
- 问题:

- 思路:
1 | 思路1: 直接对a[l-1:r]进行集合运算,返回长度,时间O(qn),空间O(n);超时 |
- 代码:
n,m = map(int, raw_input().split())
a = map(int, raw_input().split())
q = input()
d = collections.defaultdict(list)
for i,x in enumerate(a):
d[x].append(i)
def solve(l,r):
l,r = l-1, r-1
res = 0
for key in d:
x = bisect.bisect_left(d[key], l)
y = bisect.bisect_right(d[key], r)
res += (y > x)
return res
for _ in xrange(q):
l,r = map(int, raw_input().split())
print solve(l,r)
