Spark Types
Spark-Scala 数据类型
Spark SQL 具有大量内部类型表示形式,下表列出了 Scala 绑定的类型信息:
| id | Data Type | Value type in Scala | API to create a data Type |
|---|---|---|---|
| 1 | ByteType | Byte | ByteType |
| 2 | ShortType | Short | ShortType |
| 3 | IntegerType | Int | IntegerType |
| 4 | LongType | Long | LongType |
| 5 | FloatType | Float | FloatType |
| 6 | DoubleType | Double | DoubleType |
| 7 | DecimalType | java.math.BigDecimal | DecimalType |
| 8 | StringType | String | StringType |
| 9 | BinaryType | Array[Byte] | BinaryType |
| 10 | BooleanType | Boolean | BooleanType |
| 11 | TimestampType | java.Timestamp | TimestampType |
| 12 | DateType | java.sql.Date | DateType |
| 13 | ArrayType | scala.collection.Seq | ArrayType( elementType, [containsNull]) |
| 14 | MapType | scala.collection.Map | MapType( keyType, valueType, [valueContainsNull]) |
| 15 | StructType | org.apache.spark.sql.Row | tructType( fields: Array[StructField]) |
| 16 | StructField | Scala中此字段的数据类型的值类型 | StructField( name,dataType,[nullable]) |
在 Scala 中,要使用 Spark 类型,需要先导入 org.apache.spark.sql.types._:
1 | import org.apache.spark.sql.types._ |
数据类型转换
本地类型 & Spark 类型
我们经常需要在本地类型和 Spark 类型之间进行转换,以利用各自在数据处理不同方面的优势,在转化过程中本地类型和 Spark 类型要符合上表中列出的对应关系,如果无法进行隐式转换就会报错:
- 本地类型 -> Spark 类型:
- 通过本地对象创建 DataFrame:
toDF()、createDataFrame(); - 将本地基本类型转化为 Spark 基本类型:
lit(); - udf 返回值会被隐式地转化为 Spark 对应的类型;
- 通过本地对象创建 DataFrame:
- Spark 类型 -> 本地类型:
- 将 DataFrame 收集到 driver端:
collect(); - 向 udf 传递参数时,会将 Spark 类型隐式地转化为对应的本地类型;
- 将 DataFrame 收集到 driver端:
1 | import org.apache.spark.sql.functions.lit |
需要注意的是,如果传给 lit() 的参数本身就是 Column 对象,lit() 将原样返回该 Column 对象:
1 | /** |
Spark 类型 & Spark 类型
将 DataFrame 列类型从一种类型转换到另一种类型有很多种方法:withColumn()、cast()、selectExpr、SQL 表达式,需要注意的是目标类型必须是 DataType 的子类。
1 | // 示例数据 |
- 通过
withColumn()、cast():
1 | val df2 = df |
- 通过
select:
1 | val cast_df = df.select(df.columns.map { |
- 通过
selectExpr:
1 | val df3 = df2.selectExpr("cast(age as int) age", |
布尔类型
布尔类型是所有过滤的基础:
1 | df.where(col("salary") < 4000).show() |
数字类型
摘要
1 | df.describe().show() |
运算
1 | val df2 = df.withColumn("f_diff", (col("dob") - col("salary"))/col("salary")) |
统计
StatFunctions 程序包中提供了许多统计功能,可以通过 df.stat 访问。
1 | // 交叉表 |
自增 ID
monotonically_increasing_id 生成一个单调递增并且是唯一的 ID。
1 | df.withColumn("f_id", monotonically_increasing_id()).show() |
字符串类型
截取
1 | // 语法:pos 从 1 开始 |
拆分
1 | // 语法:pattern 是一个正则表达式,返回一个 Array |
拼接
1 | // 语法 |
增删两侧
1 | // 语法 |
字符替换
1 | df.withColumn("f_translate", translate(col("dob"), "36", "+-")).show() |
子串查询
1 | // 语法,other 可以是 Column 对象,将逐行判断 |
正则替换
正则详细规则参见这里。
1 | // 语法 |
正则抽取
1 | // 语法 |
日期类型
在 Spark 中,有四种日期相关的数据类型:
- DateType:日期,专注于日历日期;
- TimestampType:时间戳,包括日期和时间信息,仅支持秒级精度,如果要使用毫秒或微秒则需要进行额外处理;
- StringType:经常将日期和时间戳存储为字符串,并在其运行时转换为日期类型;
- LongType:Long 型时间戳,注意当通过 Spark SQL 内置函数返回整型时间戳时单位为秒;
本部分只介绍 Spark 内置的日期处理工具,更复杂的操作可以借助 java.text.SimpleDateFormat 和 java.util.{Calendar, Date} 使用 UDF 来解决。
日期获取
获取当前日期
1 | val df = spark.range(3) |
从日期中提取字段
1 | val tmp = spark.range(1).select(lit("2020-11-07 19:45:12").as("date")) |
获取特殊日期
1 | val tmp = spark.range(1).select(lit("2020-11-07 19:45:12").as("date")) |
类型转换
日期相关的四种数据类型之间的转换方法如下图所示,其中,格式串遵守 Java SimpleDateFormat 标准。
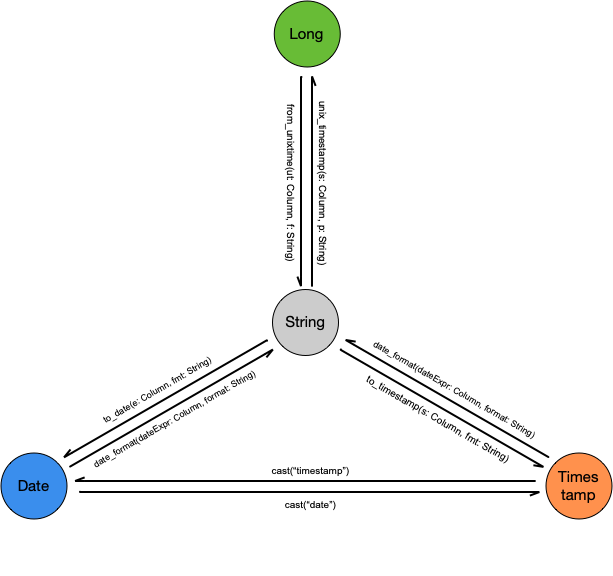
Long & String
from_unixtime 函数可以将 Long 型时间戳转化为 String 类型的日期,unix_timestamp 函数可以将 String 类型的日期转化为 Long 型时间戳。
- 语法:
1 | // 默认返回当前秒级时间戳,在同一个查询中对 unix_timestamp 的所有调用都会返回相同值,unix_timestamp 会在查询开始时进行计算 |
- 示例:
1 | val tmp = df.withColumn("long_string", from_unixtime(col("timestampLong"))) |
String & Date
to_date 函数可以将时间字符串转化为 date 类型,如果不指定具体的格式串,则等价于 cast("date");date_format 函数可以将 date/timestamp/string 类型的日期时间转化为指定格式的时间字符串,如果只是希望将他们按原样转化为字符串,也可直接通过 cast("string") 来实现。
- 语法:
1 | // 等价于 col(e: Column).cast("date") |
- 示例:
1 | val tmp = df.withColumn("date_string", date_format(col("date"), "yyyyMMdd")) |
String & Timestamp
和 string & date 之间的转换基本一致,不再赘述,这里只通过几个示例来做说明:
1 | val tmp = df.withColumn("timestamp_string", date_format(col("timestamp"), "yyyyMMdd")) |
Date & Timestamp
date & timestamp 之间的转换直接通过 cast 即可实现,无需赘言:
1 | val tmp = df.withColumn("timestamp_date", col("timestamp").cast("date")) |
日期运算
用到的时候搜索 API 即可,这里还是有必要列出最常用到的:
日期 ± 天数
1 | // 原型,start 必须是date或者可以隐式地通过 cast("date") 转化为 date (timestamp 或 yyyy-MM-dd HH:ss 格式的字符串) |
日期 - 日期
1 | // 返回 end - start 的天数 |
月份运算
1 | val tmp = df.withColumn("month_diff", months_between(col("date"), lit("2020-09-01"))) |
处理空值
最佳实践是,你应该始终使用 null 来表示 DataFrame 中缺失或为空的数据,与使用空字符串或其他值相比,Spark 可以优化使用 null 的工作。对于空值的处理,要么删除要么填充,与 null 交互的主要方式是在 DataFrame 上调用 .na 子包。
填充空值
ifnull(expr1, expr2):默认返回expr1,如果expr1值为 null 则返回expr2;只用于 SQL 表达式;nullif(expr1, expr2):如果条件为真则返回 null,否则返回expr1;只用于 SQL 表达式;nvl(expr1, expr2):同 ifnull;nvl2(expr1, expr2, expr3):如果expr1为 null 则返回expr2,否则返回expr3;
1 | df.createOrReplaceTempView("df") |
coalesce(e: Column*):从左向右,返回第一个不为 null 的值;
1 | df.select(coalesce(lit(null), lit(null), lit(1)).as("coalesce")).show(1) |
na.fill:用法比较灵活:只有 value 的类型和所在列的原有类型可隐式转换时才会填充- 如果对所有列都用相同的值填充空值,可以用
df.na.fill(value); - 如果对几个列都用相同的值填充空值,可以用
df.na.fill(value, Seq(cols_name*)); - 如果对几个列分别用不同的值填充空值,可以用
df.na.fill(Map(col->value))
- 如果对所有列都用相同的值填充空值,可以用
1 | val df = spark.range(1).select( |
删除空值
删除空值可以分为以下几种情况:
- 删除某列为空的行:直接通过
.where("col is not null")即可完成; - 删除包含空值的行:
na.drop(); - 删除所有列均为空的行:
na.drop("all")仅当改行所有列均为 null 或 NaN 时,才会删除;
1 | df.na.drop().show() |
处理复杂类型
复杂类型可以帮助你以对问题更有意义的方式组织和构造数据,Spark SQL 中复杂类型共有三种:
| id | Data Type | Scala Type | API to create a data Type |
|---|---|---|---|
| 1 | StructType | org.apache.spark.sql.Row | tructType( fields: Array[StructField]) |
| 2 | ArrayType | scala.collection.Seq | ArrayType( elementType, [containsNull]) |
| 3 | MapType | scala.collection.Map | MapType( keyType, valueType, [valueContainsNull]) |
示例数据:创建 DataFrame 时,显式定义 struct/array/map 类型
1 | val data = Seq( |
StructType
可以将 struct 视为 DataFrame 中的 DataFrame,struct 是一个拥有命名子域的结构体。
- 基于现有列生成 struct: 在 Column 对象上使用 struct 函数,或者在表达式中使用一对括号
1 | df.select(struct(col("gender"), col("salary")), expr("(gender, salary)")).show() |
- 提取 struct 中的值:点操作会直接提取子域的值,列名为子域名,特别的,
.*可以提取 struct 中所有的子域;getField方法也可以提取子域的值,但列名为完整带点号的名称
1 | df.select(coldf.select(col("f_struct.firstname"), expr("f_struct.firstname"), col("f_struct").getField("firstname"), col("f_struct.*")).show() |
ArrayType
- 基于现有列生成 array:列对象和表达式用法相同,都是在多列外使用
array函数;split、collect_list等函数也会返回 array;
1 | df.select(array(col("gender"), col("salary")), expr("array(gender, salary)")).show() |
- 提取 array 中的元素:通过
[index]按索引提取数组中的值;
1 | df.select(col("f_array").getItem(0), expr("f_array[0]")).show() |
- 处理 array 的函数:参考
org.apache.spark.functions
1 | df.select( |
MapType
- 基于现有列生成 map:Column 和表达式用法相同,
map(key1, value1, key2, value2, ...);其中,输入列必须可以被分组为key-value对,所有 key 列必须具有相同类型且不能为 null,value 列也必须具有相同类型(或者可以通过 cast 转化为相同类型);
1 | val dfmap = df.select( |
- 处理 map 的函数:

1 | dfmap |
处理 JSON
Spark 对 JSON 数据提供了一些独特的支持,可以直接在 Spark 中对 JSON 字符串进行处理,并从 JSON 字符串解析或提取 JSON 对象(返回字符串)。
- 创建一个 JSON 列:
1 | val df = spark.range(1).selectExpr(""" |
- 提取 JSON 字符串中的值:可以使用
get_json_object内联查询 JSON 对象,如果只有一层嵌套,也可以使用json_tuple
1 | val res = df |
- 将 struct/map 列转化为 json 列:
to_json函数可以将StructType或MapType列转化为 JSON 字符串;
1 | val dfjson = df.select("f_struct", "f_map") |
- 将 json 列解析回 struct/map 列:
from_json函数可以将 json 列解析回 struct/map 列,但是要求制定一个 Schema
1 | val structSchema = new StructType() |
