xgboost自从被提出来后就因其出众的效率和较高的准确度而被广泛关注,在各种比赛中大放异彩,下图即是对xgboost的完美代言:

xgboost(eXtreme Gradient Boosting)是GBDT的一个C++实现,作者为华盛顿大学研究机器学习的大牛陈天奇,他在研究中深感受制于现有库的计算速度和精度,因此着手搭建xgboost项目。在陈天奇的论文中提到了xgboost的几个主要特点:
- 加入了正则化项的结构化损失函数(叶节点数作为L1正则,叶节点输出值的平方和作为L2范数);
- 使用损失函数的二阶泰勒展开作为近似;
- 能够自动处理稀疏数据;
- 采用加权分位数算法搜索近似最优分裂点;
- 加入了列抽样;
- 加入了Shrinkage,相当于学习率缩减;
- 基于分块技术的大量数据高效处理();
- 并行和分布式计算;
原理篇
提升树、GBDT 和 Xgboost 的关系如下:
- 提升树 = 决策树加法模型 + 经验风险最小化 + 前向分布算法
- GBDT = 决策树加法模型 + 经验风险最小化 + 前向分布算法 + 梯度提升算法
- xgboost = 决策树加法模型 + 结构风险最小化 + 前向分布算法 + 损失函数二阶泰勒展开
模型(additive model)

xgboost与GBDT同为决策树加法模型:
- $f_M(x)$: 第M次迭代后的集成模型;
- $T(x;\gamma_m)$:第m次迭代的基模型(决策树),对分类问题是二叉分类树,对回归问题是二叉回归树,以下以回归树为例;
- $\gamma$:参数,{$(R_1,c_1),(R_2,c_2),…,(R_J,c_J)$}表示树的区域划分和各区域上的预测值,J是回归树的复杂度即叶子节点数;
结构风险最小化(SRM)
xgboost在其优化的损失函数中引入了正则化项:
- $J_m$:第m棵树叶子节点个数;
- $cm$:($c{m1},c{m2},…,c{mJ_m}$),第m棵树中各叶子节点的输出值;
- $\alpha$:一阶正则项系数;
- $\beta$:二阶正则项系数;
直观上通过决策树的叶子个数和叶子输出值可以对模型进行很强的控制,引入正则项后,算法会选择简单而性能优良的模型,防止过拟合。xgboost要求其损失函数至少是二阶连续可导的凸函数。
前向分步算法
xgboost与GBDT类似,采用前向分步算法来简化上述优化问题:每一步通过一个决策树来拟合当前模型预测值与真实值的残差,并将其累加至当前模型得到最新模型。
1、初始化模型:
2、对 $m=1,2,…,M$
(1)拟合决策树:
(2)更新模型:
3、最终模型:
损失函数的二阶泰勒展开
与GBDT将损失函数在当前模型下的负梯度值作为残差的近似值来拟合决策树的梯度提升方法不同,xgboost将损失函数在当前模型下的二阶泰勒展开作为近似损失函数来训练决策树:
- $gi = \frac{\partial L(y_i,f{m-1} (xi))}{\partial f{m-1}(xi)}$:为损失函数在当前模型$f{m-1}(x_i)$处的一阶偏导;
- $hi = \frac{\partial^2 L(y_i,f{m-1}(xi))}{\partial f{m-1}(xi)^2}$: 为损失函数在当前模型$f{m-1}(x_i)$处的二阶偏导;
去掉常数项C不会影响优化结果,因此损失函数变成如下形式:
使用泰勒二阶展开的优点:
xgboost使用了一阶和二阶偏导, 二阶导数有利于梯度下降的更快更准. 使用泰勒展开取得函数做自变量的二阶导数形式, 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子分裂优化计算, 本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 这种去耦合增加了xgboost的适用性, 使得它按需选取损失函数, 可以用于分类, 也可以用于回归。
引用自:@AntZ
xgboost决策树生成
确定叶子节点的最优输出值
进一步化简我们的损失函数:
其中:
因为$\alpha Jm$为常数,因此最小化损失函数就可以通过分别极小化每个叶子节点中损失值$q(c{mj})$实现。$q(c_{mj})$为凸函数,这是一个无约束的凸优化问题,求导令其等于0,得到每个叶子节点的最优输出值以及该决策树所带来的损失函数值的减少:
xgboost中每棵决策树中各叶子节点的输出值只由损失函数在当前模型的一阶、二阶导数决定,在第m次迭代时,只要我们预先计算出g和h,在训练生成一棵树模型后就可以直接计算出每个叶子节点的最优输出值。那么现在的问题就是:xgboost是根据什么条件来生成一棵合适的决策树呢?

分裂条件
与一般决策树选取最大信息增益(ID3)、最大信息增益率(C4.5)、最小基尼系数(CART)或最小方差(CART)类似,xgboost按照“最大损失减小值”的原则来选择最优切分特征和切分点。
假设我们要对某个节点进行分裂,设$R$表示该节点上所有样本的集合,$R_L,R_R$表示分裂后左右子节点中样本集,则根据损失函数一阶二阶导数可以计算出分裂前后第m棵树的损失函数减小量为:
决策树集成
shrinkage方法
在对各个基决策树进行加和集成时,xgboost采用了shrinkage(缩减)的方法来降低过拟合的风险,模型集成形式如下:
shrinkage方法最早由Friedman于1999年在《Greedy Function Approximation:A Gradient Boosting Machine》中提出。$\eta$ 取较小的值时会使得模型的泛化能力较强,该值与迭代次数具有高度的负相关,在调参时通常需要将两者一起联调。
为什么要乘一个 $\eta$ 呢,有以下三个原因:
- 训练数据由于样本量有限,存在一定的信息丢失;
- 训练数据中存在一些噪声;
- 我们的算法是把训练数据中的每一个样本都当做一个不同的维度,这必然会导致训练误差和泛化误差存在偏差;
因此,如果我们依然在每一次都取最优的$T(x;\gamma_m)$,就极有可能导致各个基学习器过拟合,通过乘以一个小于1的系数,让该模型尽量只学习到有用的信息,抑制过拟合。
特征抽样
xgboost在构造树模型时也借用了随机森林中随机选择一定量的特征子集来确定最优分裂点的做法,以防止过拟合(增加基学习器的多样性)。特征子集越大则每个基学习器的偏差就越小,但方差就越大。
xgboost性能优化
这里主要介绍xgboost对计算性能和预测结果的优化方法
分裂点搜索算法优化
- 完全式搜索:和大多数基于树的算法一样,xgboost也实现了一种完全搜索式的算法,这种搜索算法会遍历一个特征上所有可能的分裂点,分别计算其损失减少量,选择最优的分裂点。其优点是能够搜索到最优的分裂点,但缺点是当数据量很大时比较浪费计算资源,当我们的训练数据很大,以至于无法一次性加载完或者在分布式计算环境下,该算法就无能为力了。
- 分位点搜索:首先根据某个特征K的取值分布情况,选取$l$个分位点将特征划分为$l+1$个子区间(把损失函数在各个样本点的二阶偏导作为样本权重求取分位数,详情参见论文)。然后分别在每个子区间中各个样本在当前迭代中的一阶导数和二阶导数求和,得到该区间的一阶和二阶导数的汇总统计量。后面在寻找最优分裂点时就只搜索这$l$个分位点,并从这$l$个分位点中找到最好的分裂点作为最优分裂点的近似。

稀疏数据的自动识别
实际问题中我们经常遇到稀疏数据,导致数据稀疏的原因有很多种:
- 数据中包含大量缺失值;
- 统计频率为零;
- one-hot编码;
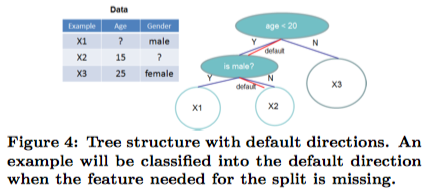
xgboost实现了一种自动处理稀疏/缺失数据的算法:xgboost为每个节点指定了一个默认方向(通过将当前节点中所有在当前特征非缺失的样本分别全部划分到左右子节点,比较两个模型相比划分前的损失减少值,将减少的多的模型中该节点的划分方向作为该节点的默认方向),当遇到缺失值时,xgbooost会将该样本划分到默认方向。在处理稀疏数据时,该算法将时间复杂度由线性缩短至与no-missing个数成正比,大大提升了计算性能。

其他性能优化
- 基于数据块的预排序:为了减小 CART 树构造 过程中的计算开销,XGBoost 在构造 CART 树之前先构造一个经过压缩处理的数 据块,该数据块中存储的是按照各特征值排序后对样本索引的指针。每次寻找最 优分裂点时只需要在这个数据块中依次遍历,然后根据其指针来提取各样本的一 阶导数和二阶导数即可。这样就不必反复地进行排序了,大大提高了计算的速度。
- Cache-aware Access 技术:如果要获取的样本点的导 数值恰好不在当前缓存中,CPU 就必须访问内存,这就延长了处理时间。为了解 决这个问题,XGBoost 采用了 Cache-aware Access 技术来降低处理时间。
- Block Compression 技术:当我们需要处理的训练数据非常大,以至于内存无法一次加载完时,xgboost将整个训 练数据集切割成多个块(block),并将其存储在外存中。在训练模型时 XGBoost 通过一个单独的线程来将需要处理的某个数据块预加载到主存缓冲区,以实现处 理操作在数据上的无缝衔接。XGBoost 不是简单的将数据分块存放在外存中,而 是采用一种按列压缩的方法对数据进行压缩,并且在读入时利用一个单独的线程 来实时解压。
- XGBoost 还通过将数据分散到多个可用的磁盘上,并为每一 个磁盘设置一个数据加载线程,这样就能同时从多个磁盘向内存缓冲区加载数据, 模型训练线程就能自由地从每个缓冲区读取数据,这大大增加了数据吞吐量。
实战篇
安装
安装官方anacanda发行版xgboost(windows\mac\linux):
1 | conda install -c anaconda py-xgboost |
使用
xgboost有两种使用方式:标准方式和sklearn方式。鉴于sklearn提供了更丰富的功能,并且使用广泛,推荐使用。
官网参考
klearn方式
1 | # 包导入方式 |
数据准备
sklearn方式对数据要求比较轻松,只要是array-like类型的就可以。
1 | # 假设数据已事先完成预处理 |
模型选择
先通过XGBClassifier构建一个“生”模型,参数取初始预估值
1 | xgb1 = XGBClassifier(learning_rate =0.1, |
参数选择
运行XGBoost之前,必须设置三类参数:
- 基本(General)参数:设置要使用的基本模型
- 提升(Booster)参数:在每一步指导每个提升(树或回归)
- 学习任务(Learning Task Parameters)参数:指导优化模型表现
基本参数
- 【booster】[默认为gbtree]:每次迭代的基本模型类型。默认为gbtree,树模型;也可以是gblinear,线性模型
- 【silent】[默认为0]:是否为静默模式。默认为0,运行时不打印running messages;若为1,则打印。
- 【nthread】[默认最大线程]:进程数。默认为最大线程。
提升参数
可以把booster参数看作是模型的旋钮,当旋钮”顺时针”滑动,模型会更复杂、学习能力也更强同时也越容易导致过拟合。
树模型和线性模型的提升参数有所不同,这里只介绍tree booster,因为它的表现远远胜过linear booster,所以linear booster很少用到。
1 | import xgboost as xgb |
XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True, objective='reg:linear', nthread=-1, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, base_score=0.5, seed=0, missing=None)
| 参数 | 含义 | 典型取值 | 说明 |
|---|---|---|---|
max_depth |
树的最大深度 | 3-10 | 越大,学习能力越强,偏差越小、方差越大,越容易过拟合 |
learning_rate |
学习速率 | 0.01-0.2 | 越大,收敛速度越快,但越粗糙 |
n_estimators |
迭代次数 | 50-1000 | 越大,偏差越小、方差先减小后增大,越容易过拟合 |
silent |
是否开启静默模式 | 0 | 静默模式开启,不会输出任何信息 |
objective |
损失/目标函数 | reg:linear | reg:linear线性回归,binary:logistic 二分类逻辑回归,multi:softmax多分类 |
nthread |
线程数 | -1 | 默认最大可能线程 |
gamma |
节点分裂所要求的最小损失函数下降值 | 0 | 越大,越不容易分列,偏差越大、方差越小,越容易欠拟合 |
min_child_weight |
最小叶子节点样本权重和 | 1 | 越大,越容易欠拟合 |
max_delta_step |
每棵树权重改变的最大步长 | 0 | 越大,越容易欠拟合,一般不用 |
subsample |
对于每棵树,随机采样样本数的比例 | 0.5-1 | 越大,学习能力越强,越容易过拟合 |
colsample_bytree |
每棵树随机采样的列数的占比 | 0.5-1 | 越大,学习能力越强,越容易过拟合 |
colsample_bylevel |
每一级的每一次分裂,对列数的采样的占比 | 1 | 越大,学习能力越强,越容易过拟合,不常用 |
reg_alpha |
L1正则化项。(和Lasso regression类似) | 1 | 越大,越容易欠拟合 |
reg_lambda |
权重的L2正则化项。(和Ridge regression类似) | 1 | 越大,越容易欠拟合,很少用 |
scale_pos_weight |
类别样本十分不平衡,加快算法收敛 | 1 | 正数 |
base_score |
初始化所有样本的预测得分 | 用于不均衡数据阈值调整 | |
seed |
随机种子数 | 用于过程复现 | |
missing |
数据中缺失值的默认值 | None | 缺省时,缺失值为np.nan |
任务参数
- 【objective】[默认为reg:linear]:可选的学习目标如下:
- “reg:linear” –线性回归。
- “reg:logistic” –逻辑回归。
- “binary:logistic” –二分类的逻辑回归问题,输出为概率。
- “binary:logitraw” –二分类的逻辑回归问题,输出的结果为wTx。
- “count:poisson” –计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7。(used to safeguard optimization)
- “multi:softmax” –让XGBoost采用softmax目标函数处理多分类问题,同时需要设置参数num_class(类别个数)
- “multi:softprob” –和softmax一样,但是输出的是ndata * nclass的向量,可以将该向量reshape成ndata行nclass列的矩阵。没行数据表示样本所属于每个类别的概率。
- “rank:pairwise” –set XGBoost to do ranking task by minimizing the pairwise loss
- 【eval_metric】[默认值根据objective参数调整]:性能指标
- rmse – root mean square error
- mae – mean absolute error
- logloss – negative log-likelihood
- error – Binary classification error rate (0.5 threshold)
- merror – Multiclass classification error rate
- mlogloss – Multiclass logloss
- auc: Area under the curve
- 【seed】[默认为0]:随机数种子,置它可以复现随机数据的结果,也可以用于调整参数
python的XGBoost模块有一个sklearn包,XGBClassifier。这个包中的参数是按sklearn风格命名的。但会改变的函数名是:
- eta ->learning_rate
- lambda->reg_lambda
- alpha->reg_alpha
- num_boosting_rounds->n_estimators
关于调节迭代次数的参数,在标准XGBoost视线中调用拟合函数时把它作为num_boost_round参数传入。在XGBClassifier中通过设置参数中的n_estimators来实现。
参考资料
官网参考
- xgboost官网的一些常用资源:
XGBoost理论
XGBoost示例
XGBoost参数
python API
- python XGBoost工作流-原版
- python XGBoost工作流-翻译
- python XGBoost工作流-示例
- XGBoost Python API
- XGBoost的源码和详细API(强力推荐)
其他参考
- 《XGBoost与案例解析》,Drxan
- 《XGBoost: A Scalable Tree Boosting System》,Tianqi Chen
- XGBoost原理解析.pdf
- 陈天奇XGBOOST.pdf
- xgboost实战
- 机器学习xgboost实战—手写数字识别
- XGBoost参数调优完全指南(附Python代码,强力推荐):有数据有代码有说明
- xgboost 调参经验-train参数说明
- xgboost 调参经验
- sklearn-metrics性能指标分类
- sklearn-gridsearch网格搜索:指定参数范围、模型、性能指标、k-fold验证、=》输出最佳参数
- xgboost-xgbcv交叉验证-迭代参数选择
- xgboost-DMatrix带权重数据导入
- XGBoost的参数-原版
- XGBoost的参数-译文
- XGBoost参数调优完全指南(附Python代码,强力推荐):有数据有代码有说明
