前言
特征工程的重要性
特征工程(Feature Engineering)是机器学习界的一个非正式话题,至今还没有一个明确的定义,大多数书籍也都以讲解算法为主,很少提及特征工程,但不可否认的是特征工程很大程度上决定了机器学习实践的成败:
Feature engineering is another topic which doesn’t seem to merit any review papers or books, or even chapters in books, but it is absolutely vital to ML success. […] Much of the success of machine learning is actually success in engineering features that a learner can understand.
— Scott Locklin, in “Neglected machine learning ideas”
创造新的特征是一件十分困难的事情,需要丰富的专业知识和大量的时间。机器学习应用的本质基本上就是特征工程。
——Andrew Ng
The algorithms we used are very standard for Kagglers. […] We spent most of our efforts in feature engineering.
— Xavier Conort, on “Q&A with Xavier Conort” on winning the Flight Quest challenge on Kaggle
虽然机器学习的最终效果是由数据、模型、参数、评价指标等众多因素相互影响的结果,但是好的特征能够为模型和参数的选择提供更大的空间和灵活性,所以在大数据竞赛中经常流行着这样一句话:
数据和特征决定了性能的上限,不同的算法只能去逼近这个上限。
什么是特征工程
这里我们尝试给出特征工程的一个定义:
特征工程是利用领域知识或自动化手段将原始特征空间映射到新的特征空间,以使隐藏在数据和问题中的模式能够更好地被呈现给我们所选择的模型,从而提升模型在特定问题上的预测精度的过程。
在特征工程的定义中涉及到了以下概念:
- 所要解决的问题:分类、回归、标注等…
- 拿到的原始数据:最初收集到的数据
- 领域知识:通常新的特征融合了我们关于具体问题和具体数据的领域知识
- 自动化手段:在没有领域知识的前提下仍然可以通过一些自动化的手段实现特征工程
- 通过特征工程得到的新的特征空间
- 所选择的模型:朴素贝叶斯、SVM、决策树等
- 模型性能的评价指标:均方误差、精度、F1、AUC等
特征工程是一个数据呈现的问题:你必须将你的输入转化为算法能够理解的东西。
特征工程是一门艺术:数据是各种各样的,特征工程没有通用有效的方法,必须不断地从实践中学习什么时候该用哪种特征工程方法。
feature engineering is manually designing what the input x’s should be.
— Tomasz Malisiewicz
特征变换
离散特征
- one-hot编码
- 类别合并
连续特征
标准化
标准化是特征无量纲化的一种方法,前提是特征服从正态分布,标准化后可以将其转化为标准正态分布。
- 标准化
- 归一化
- 离散化
- 对数变换
特征组合
求积取出不同特征进行加减乘除产生新的备选特征
将原始特征组合成一组具有物理意义或统计意义的特征;
有时可以通过自动化手段对特征进行加减乘除来产生新的特征,然后评估所有特征的重要度,选择重要程度高的特征来做训练,但不建议使用自动循环来对所有特征获取相关的操作,这会导致“特征爆炸”。
- 两个特征相加:你想要通过预售数据来预测收入,通过sales_blue_pens和sales_black_pens相加,你可以得到sales_pens的总销量;
- 两个特征相减:同样也可以根据房屋的建造时间(house_built_date )和购买时间差(house_purchase_date)来得到房屋购买时的年限(house_age_at_purchase)
- 两个特征相乘:当你要进行售价测试的时候,你可以通过售价price和指示器变量conversion相乘来得到新的特征earnings。
- 两个特征相除:当你在对市场竞争对手分析时,可以通过点击率(n_clicks)和网页打开次数(n_impressions)相除来得到点击率click_through_rate来更好的分析对手数据。
特征拆分
- 方法描述:将原始特征拆分为多个特征;比如将身份证信息拆分为地域和年龄。
- 适用场景:单特征蕴含多种信息;
- 影响评估:需要领域知识
特征选择
特征选择(feature selection):从给定特征集合中选择出相关特征子集的过程
- 相关特征:对当前学习任务有用的特征;需要在特征选择中留下的特征;
- 无关特征:对当前学习任务没什么用的特征;需要在特征选择中去掉的特征;
- 冗余特征:它们所包含的特征能从其他特征中推演出来;只有在冗余特征能够对应于完成任务所需的“中间概念”时,冗余特征才是有益的,否则建立去掉;
特征选择的作用:
- 降维:减轻维数灾难,提高计算效率;
- 降噪:无关特征相当于数据中的噪声;
特征选择的步骤:子集搜索和子集评价共同构成完整的特征选择方法
- 子集搜索:获取特征子集的环节;
- 子集评价:评价特征子集的环节;
特征选择的分类:按照特征选择与模型训练的时机关系
- 过滤式选择:是在模型训练之前进行的特征选择
- 首先对特征重要度进行排序;
- 选择其中前k个最重要的特征作为特征子集;
- 模型训练;
- 包裹式选择:是在模型训练之后进行的特征选择
- 通过某种方式产生不同的特征子集;
- 通过交叉验证选出性能最好的特征子集;
- 嵌入式选择:是在模型训练过程中进行的特征选择
- 在模型训练过程中自动进行特征选择;
过滤式选择(filter)
Relief
Relief是一种典型的过滤式特征选择方法,其核心思路是:计算每个特征的相关统计量,然后选取相关统计量最大的前k个特征,特征A的相关统计量等于所有样本的猜错邻近与猜对邻近在该特征上的距离差之和:
- $\delta ^j$:第j个特征的相关统计量;
- $x_i^j$:第i个样本在第j维特征上的值;
- $x_{i,nm}^j$:第i个样本的猜错邻近(异类样本中的最邻近)在第j维特征上的值;
- $x_{i,nh}$:第i个样本的猜中邻近(同类样本中的最邻近)在第j维特征上的值;
- $diff(a,b)$:对a,b的某种距离度量,如果是分类特征,当a=b时$diff(a,b)=0$,否则等于1,如果是连续特征,$diff(a,b)=|a-b|$,a,b已规范化到[0,1];
- Relief只需在数据集的采样上而不需要在完整数据集上进行;时间开销随采样次数以及原始特征数线性增长
Relief是为二分类问题设计的,其变体Relief-F可以扩展到多分类问题,只需要在每一个异类中找到一个猜错近邻即可:
- $p_l$:第l类样本在数据集D中所占比例
- $x_{i,l,nm}^j$:与第i个样本在特征j上的猜错邻近(猜错为l类)
特征重要度排序
首先按照重要度(特征与标签的相关性)对特征排序,之后选取前k个最重要的特征作为特征子集,对模型进行训练。
评估特征重要度的常用方法:
- Pearson皮尔逊相关系数;
- Gini-index基尼系数;
- IG信息增益(互信息);
- 卡方检验;
包裹式选择(wrapper)
包裹式选择是为给定模型量身定做的特征子集,最终效果要比过滤式选择更好,但因为需要多次训练,计算开销通常要比过滤式选择大得多。
LVW
LVW(拉斯维加斯方法)是典型的包裹式选择,其基本思路是:每次随机选取一个特征子集,使用交叉验证评估模型效果,通过一定次数的迭代,最终选出效果最好的特征子集。
前向搜索和后向搜索
- 前向搜索:
- 先将每个单特征作为特征子集,通过交叉验证选出其中最优参数{$a_1$};
- 再从剩下特征中选取一个新特征加入到特征子集中,通过交叉验证选出其中最有参数{$a_1,a_2$};
- 重复以上过程,直至在第k+1轮时,最优的候选不如上一轮的选定集,则停止迭代,并将上一轮的子集作为最优子集;
- 后向搜索:
- 开始将所有特征纳入特征子集,进行评估;
- 去掉一个特征,通过交叉验证选取最优的特征子集;
- 重复以上过程,直至该次最优特征子集不比上一轮特征子集好,则停止迭代,并将上一轮特征子集作为最优子集;
评价:
- 优点:操作简单,对过拟合问题具有较高的鲁棒性;
- 缺点:是一种贪心策略,忽略了特征之间的相关性,可能会选择冗余特征;同时没有考虑特征的任意组合可能会带来的效果;
- 时间开销比较大;
嵌入式选择(embedding)
L1正则
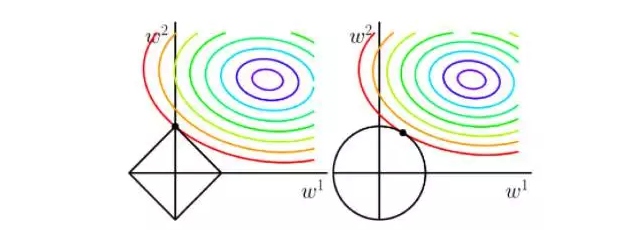
L1正则因为可以得到稀疏解(只有部分参数非零),因此可被视为一种嵌入式特征选择方法。
解释:如果做出非正则项和L1正则项损失函数等值线,整体损失会在二者相交处取到最小值,L1正则等值线为菱形形状,交点更容易出现在坐标轴上,即使得某些参数分量为零。
决策树
决策树节点划分特征(信息增益、信息增益比、基尼系数、平法误差)所组成的集合就是所选出的特征子集,决策树本身即可被看做是一种嵌入式特征选择方法。
特征提取
PCA
时间特征变换
深度学习
深度学习调参过程也可看做是对特征进行选择
