朴素贝叶斯(naive Bayes,NB)是基于贝叶斯定理与特征条件独立性假设的分类方法。其模型是通过学习先验概率和类条件概率来得到后验概率的生成式模型。其策略为后验概率最大,等价于0-1损失下的期望风险最小化策略。其算法为通过极大似然估计来求解各项概率。
模型
贝叶斯通过训练数据学习联合概率分布$p(x,y)$,具体地:
后者有指数级的参数,其估计实际是不可行的,NB对类条件概率做出了条件独立性假设,将参数个数降到线性的,朴素因此得名:
由贝叶斯定理和全概率公式我们可以得到贝叶斯公式:
对不同的分类,分母都相同,因此贝叶斯模型可表示为:
策略
后验概率最大(MAP)等价于0-1损失下的期望风险最小化的策略:
为了极小化期望风险,可以对每一个$X=x$进行极小化:
算法
不同的朴素贝叶斯方法的区别仅在于对特征的类条件概率分布 $P(x_i \mid y)$ 的假设不同,它们都是用极大似然的方法来估计分布参数。
高斯朴素贝叶斯(Gaussian Naive Bayes)
高斯朴素贝叶假设所有特征的类条件概率服从高斯分布(当特征为连续时一般选用高斯贝叶);
采用极大似然法估计 $\sigma_y$ 和 $\mu_y$。
多项式朴素贝叶斯(Multinomial Naive Bayes):
多项式朴素贝叶斯假设所有特征的类条件概率服从多项式分布,在类别为$ck$条件下,特征$X^d$的概率分布可以用一个参数向量$\theta^d_k = (\theta^d{k1},\ldots,\theta^d_{kn}) $来表示(当特征为多类别离散变量时选用多项式NB);
可以用极大似然法来估计相应的概率:
- $N_k$:所有样本中类别为$c_k$的个数;
- $N_{k,x^d}$:类别为$c_k$且第d维为$x^d$的样本个数;
平滑版极大似然:极大似然估计可能会出现估计的概率为0的情况,影响侯艳艳概率的计算,使分类出现偏差,可以用平滑方法解决这一问题,具体的就是在计算每个概率时,我们在分母的范围内为分子的每种可能结果加$\lambda$:
- K:y类别个数;
- $s_d$:数据集中当类别为$c_k$时,第i维坐标可能取值个数;
- $\lambda$: 取1时叫拉普拉斯平滑
伯努利朴素贝叶斯( Bernoulli Naive Bayes)
伯努利朴素贝叶斯假设特征的类条件分布为伯努利分布(当特征为二值特征时使用):
通过极大似然估计p。
实例
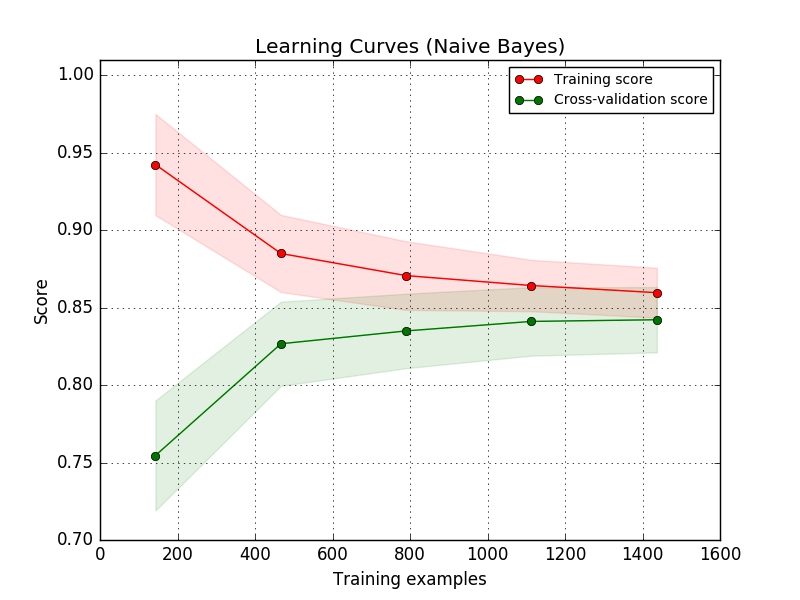
比较朴素贝叶斯与SVM的学习曲线:
1 | import numpy as np |
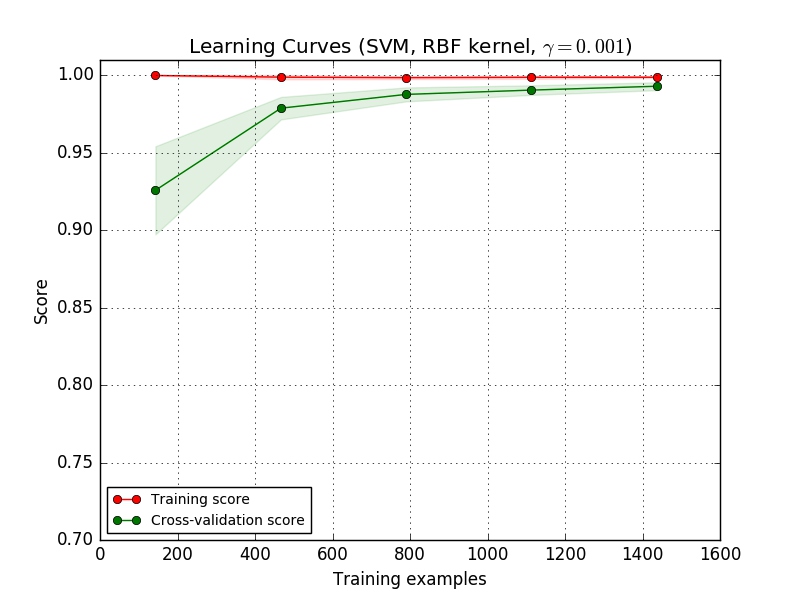
- 对于SVM(复杂模型):当数据量小的时候,训练误差为0,但是测试误差较大;随着训练数据增加,训练误差缓慢增加,验证误差逐渐下降;当数据量足够大的时候,训练误差和测试误差维持在一个较低水平;
- 对于朴素贝叶斯(简单模型):当数据量小的时候,训练误差相对复杂模型更大,验证误差也比较大;随着数据量增加,训练误差迅速增加,验证误差不断下降;当数据量足够大的时候,训练误差和测试误差维持在一个较高水平;
评价
- 优点:
- 实现简单
- 对缺失数据不敏感
- 适合增量学习
- 缺点:
- 朴素贝叶斯建立在独立性假设的基础上,当特征间相关性较大时,模型效果不好;
- 不好的先验假设会影响模型性能
- 对输入数据的表达形式比较敏感
