问题
类别不平衡(class-imbalance)是指在分类任务中不同类别的训练样本数差别很大的情况。类别不平衡问题在实际数据中是很常见的,比如在癌症检查中可能只有极少部分病人患上了癌症,而其余大多数样本都是健康的个体;又比如欺诈识别,欺诈样本与正常样本的比例可能会达到1:100000。
精度是在评估分类模型性能时最常用的一个指标,如果不同类别的训练样例数目差别很大(正例:负例 = 1:99),学习模型只需要返回一个永远将样本预测为反例的学习器,就能达到99%的精度,然而这样的学习器往往没有价值,这个精度并不能反映学习器的性能,只是反映了类别的分布。
分析
以线性分类器为例,在我们使用$y=w^Tx+b$对新样本x进行分类时,事实上是用预测值与一个阈值进行比较,例如通常在y>0.5时盼为正例,否则为反例。y实际表达了是正例的可能性,决策器的分类规则为:
当正负样例不同时,令$m^+$表示正例数目,$m^-$表示负例数目,则观测几率为$\frac{m^+}{m^-}$,通常我们假设观测几率代表了真实几率,因此只要分类器的预测几率高于观测几率,就判为正例:
但是我们的分类器是基于第一个式子来进行决策的,因此需要对其观测值进行调整,使得在基于第一个式子来决策时实际是在执行第二个式子:
这就是类别不平衡学习的一个基本策略——再缩放,虽然思路简单,但是实际操作却并不平凡,现有技术大体上有三种做法:过采样、欠采样、移动阈值。
再缩放也是代价敏感学习的基础,只需将式中$\frac{m^-}{m^-}$用$\frac{cost^+}{cost^-}$替代即可,其中$cost^+$是将正例判为负例的代价。
接下来简单对常用的过采样和欠采样算法做一说明,学习不均衡学习最好的方式就是学习imbalanced-learn的API。
过采样(oversampling)
- 原理:增加训练集中少数类样本,以使各类别样本数相对均衡;
- 实现:简单复制、设置权重、插值产生;
- 评价:简单对少数派样本重复抽样,容易造成过拟合;
- 代表算法:SMOTE,通过对训练集中的正例进行插值产生额外的正例;
过采样和交叉验证
过采样只能应用于训练集,也就是说,当我们同时需要进行过采样和交叉验证时,应该在划分出训练集和验证集之后,针对新的训练集进行过采样,这样就可以避免将验证集信息“泄露给”训练集,造成过拟合,见下图:
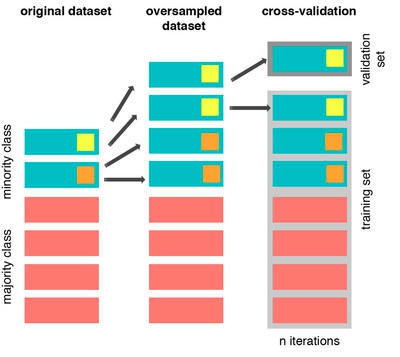
最左边那列表示原始数据,里面包含了少数类下的两个样本。我们拷贝这两个样本作为副本,然后再进行交叉验证。在迭代的过程,我们的训练样本和验证样本会包含相同的数据,如最右那张图所示,这种情况下会导致过拟合或误导的结果,合适的做法应该如下图所示。
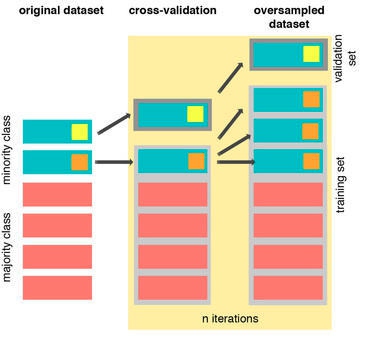
也就是说我们每次迭代做交叉验证之前先将验证样本从训练样本中分离出来,然后再对训练样本中少数类样本进行过采样(橙色那块图所示)。在这个示例中少数类样本只有两个,所以我拷贝了三份副本。这种做法与之前最大的不同就是训练样本和验证样本是没有交集的,因而我们获得一个比之前好的结果。即使我们使用其他的交叉验证方法(譬如 k-flod)或其他的过采样方法(如SMOTE),做法也是一样的。
随机上采样
随机上采样原理
随机过采样是随机在少数样本中抽样生成新副本,与原始数据共同构成新的均衡数据集的方法:
- 在训练集的少数类集合中随机选中一些样本;
- 复制这些样本生成样本集E;
- 将新样本集E添加到原始训练集集中,得到新的训练集;
随机上采样代码示例
1 | from sklearn.datasets import make_classification |

SMOTE
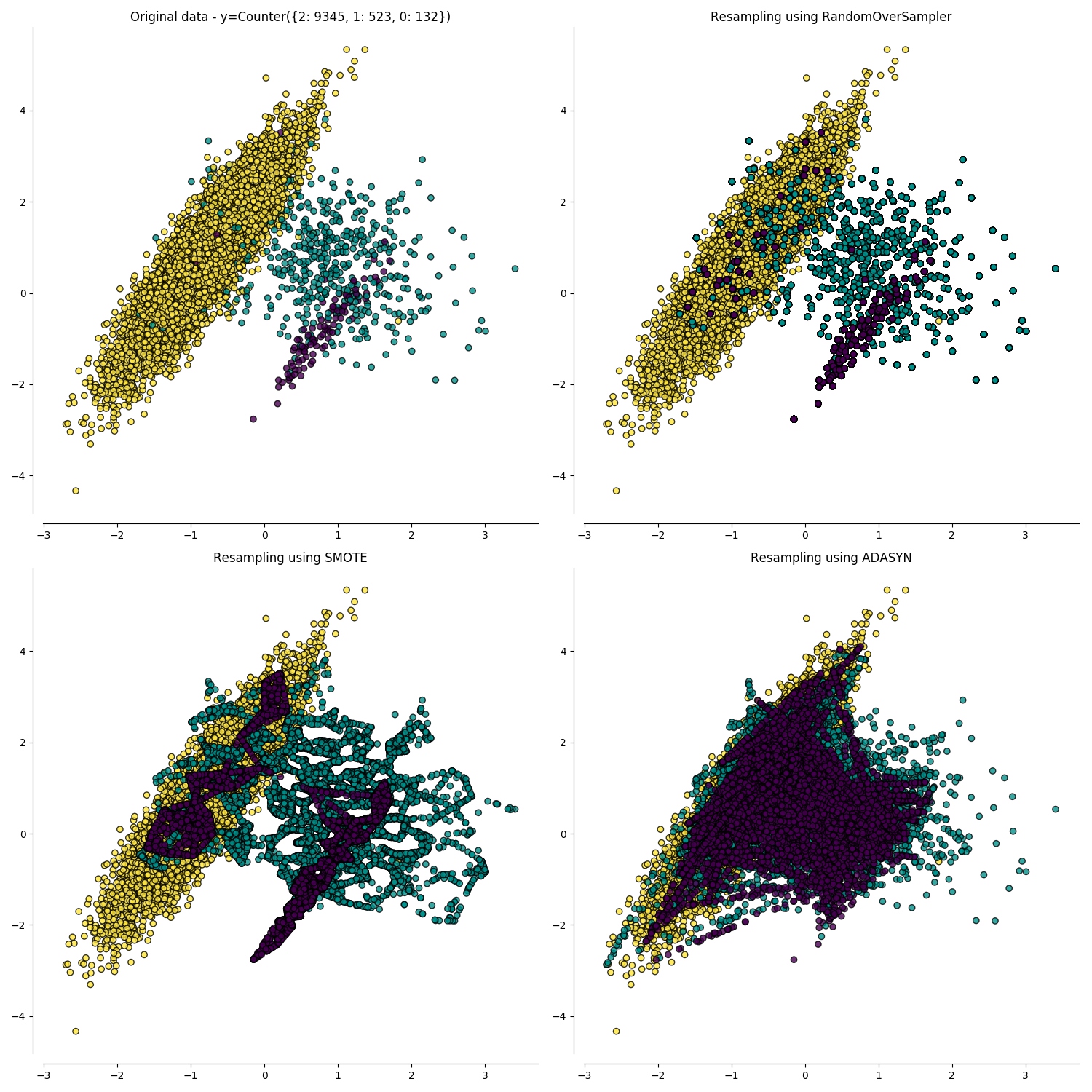
SMOTE(Synthetic Minority Over-sampling Technique,合成少数上采样) 方法并不是采取简单复制样本的策略来增加少数类样本, 而是通过分析少数类样本来创建新的样本的同时对多数类样本进行欠采样。正常来说当我们简单复制样本的时候,训练出来的分类器在预测这些复制样本时会很有信心的将他们识别出来,你为他知道这些复制样本的所有边界和特点,而不是以概括的角度来刻画这些少数类样本。但是,SMOTE 可以有效的强制让分类的边界更加的泛化,一定程度上解决了不够泛化而导致的过拟合问题。在 SMOTE 的论文中用了很多图来进行解释这个问题的原理和解决方案,所以我建议大家可以去看看。
但是,我们有一定必须要清楚的是 使用 SMOTE 过采样的确会提升决策边界,但是却并没有解决前面所提到的交叉验证所面临的问题。 如果我们使用相同的样本来训练和验证模型,模型的技术指标肯定会比采样了合理交叉验证方法所训练出来的模型效果好。
SMOTE样本生成的原理
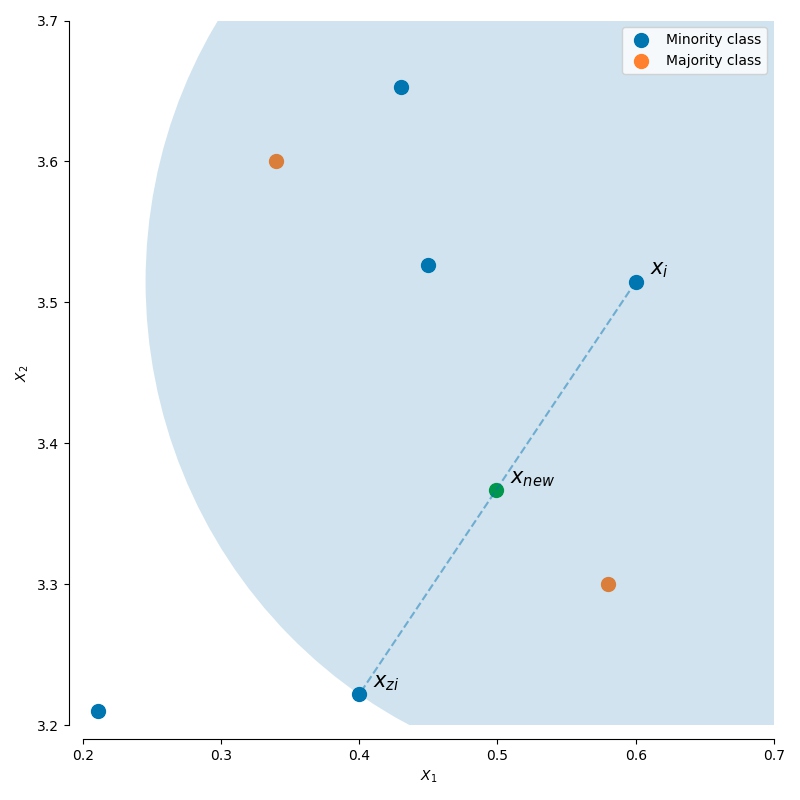
SMOTE和ADASYN采用相同的算法来生成新的样本:对于一个样本$xi$,从它的k邻近样本点中随机选择一个邻居$x{zi}$,随机在它们连线上生成一个新的样本:
SMOTE原理如下图:
SMOTE代码样例
1 | from imblearn.over_sampling import SMOTE, ADASYN |
欠采样(undersampling)
- 原理:减少训练集中多数类的样本,以使各类别样本数相对均衡;
- 实现:直接丢弃、设置权重、ENN、集成方法;
- 评价:随机丢弃多数类样本,可能丢失一些重要信息造成欠拟合;
- 代表算法:
- ENN:删除那些类别与其最近的三个近邻样本中的两个或两个以上的样本类别不同的样本;
- easyEnsemble:利用集成学习机制,将负例划分为若干集合供不同学习器使用,这样对每个学习器来说都进行了欠采样,但在全局看来却不会丢失重要信息;
随机欠采样
随机从原始数据集中的多数类中删除一些样本。
ENN
随机欠抽样方法未考虑样本的分布情况,采样具有很大的随机性,可能会删除重要的多数类样本信息。针对以上的不足,Wilson 等人提出了一种最近邻规则(edited nearest neighbor: ENN):
- 基本思想:删除那些类别与其最近的三个近邻样本中的两个或两个以上的样本类别不同的样本
- 缺点:因为大多数的多数类样本的样本附近都是多数类,所以该方法所能删除的多数类样本十分有限
easyEnsemble
- 首先通过从多数类中独立随机抽取出若干子集
- 将每个子集与少数类数据联合起来训练生成多个基分类器
- 最终将这些基分类器组合形成一个集成学习系统
EasyEnsemble 算法被认为是非监督学习算法,因此它每次都独立利用可放回随机抽样机制来提取多数类样本
结合过采样和欠采样

移动阈值(threshold-moving)
- 原理:不改变训练集,但将$\frac{\hat{y}}{1-\hat{y}} = \frac{y}{1-y} \times \frac{m^-}{m^+}$嵌入到决策过程中;
