广度优先搜索(Breadth-First-Search,BFS):类似于二叉树的层序遍历,首先访问起始顶点v,接着依次访问v的所有未被访问的邻接点w1,w2,…,再依次访问w1,w2,…所有未被访问的邻接点…,直至所有顶点都已被访问。类似的思想还应用于Prime最小生成树算法和Dijkstra单源最短路径算法。
BFS能够发现图中关于源节点的“层次结构”,BFS算法只有在发现所有距离源节点s为k的所有节点之后,才会发现距离源节点s为k+1的其他节点。因此BFS常被用来求解多对多关系中的层次依赖问题,如单源最短距离、凸台积水等问题。
理论篇
BFS算法模板
为了深入理解BFS的搜索过程,我们通过一些辅助数据结构来追踪算法进展:
- 顶点颜色:灰色是已发现和未发现的边界
- 白色顶点:未被发现的顶点
- 灰色顶点:顶点已被发现,但是顶点的邻接点尚未被完全发现
- 黑色顶点:顶点以及它所有的邻接点都已被发现
- 顶点的父节点:记录每个顶点在当前搜索过程中的父亲节点,通过各个节点的父亲节点可以方便地构造出一棵广度优先生成树
- 顶点的层数:各个顶点距离源顶点的距离,对于同一个源节点来说,每层节点的遍历顺序不同,对应的广度优先生成树可能不同,但是每个顶点到源节点的距离是唯一的
BFS标准模板
- 问题:按照广度优先的顺序依次遍历图中每个顶点,记录每个顶点的单源距离和父节点
- 思路:使用队列,循环父出子进,直至队列为空
1 | 1. 初始化辅助数据结构: |
- 代码:
1 | import collections |
- 时间复杂度分析:邻接表O(V+E),邻接矩阵 $O(V^2)$
- 对队列的操作:因为每个节点只出队入队一次,所以队列操作的时间复杂度为O(V)
- 搜索邻接点:每条边都会被遍历一次,如果使用邻接表,O(E),如果使用邻接矩阵,$O(V^2)$
- 空间复杂度分析:使用了队列,最坏的情形下O(V)
整层遍历
- 问题:有很多情形,需要对图中的节点进行整层处理:
1 | 1. 求每层节点的统计量; |
- 思路:与标准写法类似,只是整层出整层入
- 代码:
1 | def bfs(G, V, s): |
BFS基本应用
求广度优先生成树
- 问题:根据BFS搜索过程得到的各节点的父亲节点,计算对应的生成树
- 思路:父节点为None的顶点作为根节点,以邻接表形式表示树
- 代码:
1 | def get_tree(fathers): |
求单源最小距离
- 问题:求图中每个顶点到源节点的最小距离
- 思路:单源最小距离既是边的权值为1的单源最短路径,可以用类似于证明Dijkstra的方法来证明BFS得到的各节点的层数既是节点到源节点的最短距离。
- 代码:
1 | levels = bfs(G,s)[1] |
打印广度优先搜索树中的单源最小路径
- 问题:给定图中某个节点,打印源节点到该节点的最短路径
- 思路:根据BFS得到的节点的父节点关系,打印源节点s到任意节点v在广度优先搜索树中的最短路径
- 代码:
1 | def print_path(father, s, v): |
打印到指定节点所有的单源最短路径
- 问题:找到源节点s到给定节点v所有最短路径
- 思路:BFS+DFS。
- BFS得到父节点字典:因为同层节点的不同搜索顺序会导致生成的广度优先搜索树也不同,源节点到给定节点的最短路径可能不止一条。我们需要在广度优先遍历时找到每个节点在上一层所有可能的父节点,困难在于,当我们u的未被访问的邻接点v时,只是找到了v的一个可能的父节点,在与u同层的后续节点中还可能存在v的父节点。如果上一层节点没有完全出队,那么下一层节点对上一层节点就应该是未访问的,同时在寻找上一层节点u的邻接点时,那些和u在同层或更早层的节点对于u来说应该是已访问的。解决办法是,通过逐层遍历,将新一层入队的元素标记为灰色,将旧的已入队的元素标记为黑色,灰色节点对于当前出队层节点是透明的,黑色节点对当前层出队层节点是不透明的。
- DFS从父节点中找到s到v所有的最短路径
- 代码:
1 | def print_paths(G, V, s, v): |
具体实例详见Leetcode126 单词接龙 II。
寻找最近公共祖先
1 | class Solution(object): |
实战篇
应用场景
BFS实际多用于求解“单源最短距离”和“层次依赖问题”:
- 单源最短距离(无权)问题:
- 迷宫问题:走出迷宫最少步数,关键是定义好状态参数
- 单词接龙:一个单词到另一个单词的最短距离,关键是定义好相连关系
- 求树中到指定节点距离为k的所有节点:先将树转化为图
- 层次依赖问题:
- 凸台积水问题:从边界向内更新水位
定制化 BFS
BFS用于解决实际问题的一般步骤:
1 | 1. 定义图的数据结构:从实际问题中抽象出相互联系的可区分的状态 |
解决好BFS问题的核心在于定义好合适的状态,唯一性是定义状态的重要依据!!!最典型的代表参见“迷宫找钥匙”。
LeetCode典型题目
[LeetCode 863. 二叉树中所有距离为 K 的结点]
- 问题:给定一个二叉树(具有根结点 root), 一个目标结点 target ,和一个整数值 K 。返回到目标结点 target 距离为 K 的所有结点的值的列表。 答案可以以任何顺序返回。输入:
root = [3,5,1,6,2,0,8,null,null,7,4],target = 5, K = 2,输出:[7,4,1]
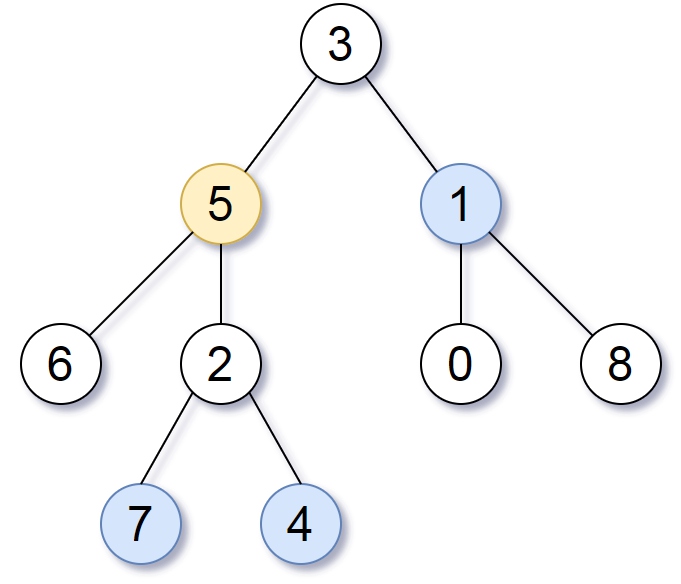
- 思路:先将树转化为无向图,再通过BFS求出第K层的所有顶点
1 | 1. 构建图的数据结构:首先遍历整棵树,构建图的数据结构 |
- 代码:
1 | def distanceK(self, root, target, K): |
[LeetCode 126. 单词接龙 II]
- 问题:给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:每次转换只能改变一个字母。转换过程中的中间单词必须是字典中的单词。
1 | 输入: |
- 思路:BFS+DFS
- 数据结构:每个单词作为一个节点,单词间相差一个字母代表单词间有边;众多单词中判断单词间是否有边,普通方法需要遍历两次,时间复杂度为O(n2),如果将每个单词的每个字母用_掩码代替,如果代替后掩码相同说明两个单词有边,只需用一个字典维护掩码:[单词]的映射,寻找一个单词的邻接点时,该单词的所有掩码对应的单词都是它的邻接点;考虑单词长度不大,构建数据结构只需要O(n)的时间复杂度;
- BFS算法:通过BFS可以找到每个节点在上一层中的所有父节点,技巧在于将之前层的节点标位黑色,将当前层已发现的节点标记为灰色,将未访问节点标记为白色,在统计父节点的孩子时,遍历其邻接点中非黑节点,将邻接点中白色节点入队标灰,最后得到父节点字典
- DFS算法:
- 代码:从结束单词除法,向上遍历其所有可能的父节点,如果遇到初始节点则说明找到一组解,进行收集,返回最后收集到的所有最短路径
1 | from collections import deque |
[LeetCode 407. 平台接雨水 II]
- 问题:给定一个m x n的矩阵,其中的值均为正整数,代表二维高度图每个单元的高度,请计算图中形状最多能接多少体积的雨水
- 思路:BFS确定平台水面最大深度
- 数据结构:平台位置作为一个顶点,位置相邻说明有边
- BFS:
- 边界最大水深即为边界平台高度,加入队列
- 出队一个平台i,更新邻接点j水面深度,如果更新成功则将邻接点入队,更新规则:limit=max(heightMap[j],h[i]),h[j] > limit
- 统计最终平台水面高度-平台高度之和
- 代码:每个节点最多被更新四次,故时间复杂度为O(m*n)
1 | def trapRainWater(self, heightMap): |
以上方法对于一维平台接雨水同样适用,参见42. 接雨水。
[LeetCode 864. 获取所有钥匙的最短路径]
- 问题:给定一个二维网格 grid。 “.” 代表一个空房间, “#” 代表一堵墙, “@” 是起点,(”a”, “b”, …)代表钥匙,(”A”, “B”, …)代表锁。我们从起点开始出发,一次移动是指向四个基本方向之一行走一个单位空间。我们不能在网格外面行走,也无法穿过一堵墙。如果途经一个钥匙,我们就把它捡起来。除非我们手里有对应的钥匙,否则无法通过锁。假设 K 为钥匙/锁的个数,且满足 1 <= K <= 6,字母表中的前 K 个字母在网格中都有自己对应的一个小写和一个大写字母。换言之,每个锁有唯一对应的钥匙,每个钥匙也有唯一对应的锁。另外,代表钥匙和锁的字母互为大小写并按字母顺序排列。返回获取所有钥匙所需要的移动的最少次数。如果无法获取所有钥匙,返回 -1 。
- 示例:
1 | 输入:[ "@ . a . #", |
- 思路:BFS
1 | 思路:单源最短距离问题,找到所有钥匙返回到源节点的距离 |
- 代码:
1 | def shortestPathAllKeys(self, grid): |
- 反思:复杂问题没什么可怕的,只要抽象出合适的数据结构,就会发现还是常规问题!本题的核心在于使用位置和钥匙集来标识一个状态
[LeetCode 815. 公交路线]
- 问题:
1 | 我们有一系列公交路线。每一条路线 routes[i] 上都有一辆公交车在上面循环行驶。例如,有一条路线 routes[0] = [1, 5, 7],表示第一辆 (下标为0) 公交车会一直按照 1->5->7->1->5->7->1->... 的车站路线行驶。 |
- 思路:
1 | 思路:仍然是单源最短距离问题,BFS求解 |
- 代码:
1 | def numBusesToDestination(self, routes, S, T): |
[LeetCode 847. 访问所有节点的最短路径]
- 问题:
1 | 给出 graph 为有 N 个节点(编号为 0, 1, 2, ..., N-1)的无向连通图。 |
- 思路:
1 | 最短距离问题:BFS |
- 代码:
1 | def shortestPathLength(self, graph): |
[LeetCode 854. 相似度为 K 的字符串]
- 问题:如果可以通过将 A 中的两个小写字母精确地交换位置 K 次得到与 B 相等的字符串,我们称字符串 A 和 B 的相似度为 K(K 为非负整数)。给定两个字母异位词 A 和 B ,返回 A 和 B 的相似度 K 的最小值。
1 | 输入:A = "abc", B = "bca" |
- 思路:
1 | 思路1:最短距离问题,考虑BFS,超时 |
- 代码:
1 | def kSimilarity(self, A, B): |
[LeetCode 199. 二叉树的右视图]
- 问题:给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
1 | 输入: [1,2,3,null,5,null,4] |
思路:整行BFS,每行返回最后一个节点值
代码:
1 | def rightSideView(self, root): |
[LeetCode 279. 完全平方数]
- 问题:给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, …)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。如:12= 4 + 4 + 4。
- 思路:实质也是单源最短路径问题,最坏时间复杂度O(dn)
1 | 1. 数据结构: |
- 代码:
1 | def numSquares(self, n): |
- 另一种思路:本体最快的解法是利用数论中的四数平方和定理与三数平方和定理
1 | 思路2: |
- 代码:
1 | def numSquares(self, n): |
