我们生活在一个相信大数据能够解决所有问题的时代,然而数据远非万能,数据可以告诉你服药的病人比不服药的病人康复得快,却不能告诉你原因何在。也许,那些服药的人只是因为他们支付得起,即使不服用这种药,他们也能恢复得更快。正如 Kendall 和 Stuart 所说,统计关系无论有多强,有多紧密,也决不能建立起因果关系,因果关系的概念来自统计学之外的某个理论。
因果关系(causality)
因果观念是人类认知事物的重要方式,我们相信,世界并非是由简单的事实堆砌而成,相反,这些事实是通过错综复杂的因果网络联系在一起的,科学正是建立在因果律的基础之上的。关于因果的讨论,已经持续了上千年,至今仍没有统一定论,在正式讨论“因果推断”之前,我们有必要搞清楚,当我们提到“因果”时,究竟是在谈论着什么。
神话时代
在神话思维时代,人类对诸如雷电、地震等自然现象都会归结为某个神灵的意志。这种拟人化的目的归因,是人类试图捕捉现象背后本质因果思维的最初尝试,并发展出交感巫术、祈祷等手段与神灵沟通,从而对自然过程进行干预。
希腊时代
人类文明的轴心时代,是古希腊人最早发扬了理性精神。哲学和科学的诞生,不仅来自经验知识,更因为是有数学和几何。古希腊最早的哲学家,包括泰勒斯、毕达哥拉斯等,都同时也是数学家和自然科学家。数学对象之间的必然关系,放到经验世界,就产生了让哲学脱胎于神话的第一次天问:“世界是如何起源的?从此人类以理性思维探讨世界秩序成为了可能。

希腊哲学家对世界起源的回答,无论是水、气、火、数、逻各斯或无定形,最后都被亚里士多德总结为四种原因:
- 质料因(Matter - material cause):构成事物的材料,例如木材就是桌子的质料因;
- 形式因(Form - formal cause):构成事物的样式,例如木工心中桌子的样式,就是桌子的形式因;
- 动力因(Agent - efficient cause):构成事物的过程,例如木工制作桌子的过程就是桌子的动力因;
- 目的因(Purpose - final cause):构成事物的目的,例如放置物品就是桌子的目的因;
理性主义
17 世纪,德国数学家和哲学家莱布尼茨,将自己的哲学建立在两个逻辑前提之上:矛盾律(在同一时刻,某个事物不可能在同一方面既是这样又不是这样)和充分理由律(任何事物都有其存在的充足理由)。这两个前提又都建立在一种“分析”命题的概念之上,而所谓的分析命题就是谓项被包含在主项之中的命题 —— 例如,“所有的白种人都是人”。矛盾律所陈述的是“所有分析命题都是真命题”,充分理由律所陈述的则是“所有的真命题都是分析命题”。这一点不仅适用于逻辑陈述,甚至对于那些我们必须当作关于实际问题的经验性陈述也适用。如果“我”做一次旅行,“我”的概念一定自永恒以来就将这次旅行的概念包括在内了,这次旅行就是“我”的谓项。
19 世纪德国哲学家、唯意志论创始人叔本华,在博士论文《充足理由律的四重根》中给出了莱布尼茨的充足理由律的四种表现形式:
- 因果关系(Becoming):生成/变化的充足理由律,适用于现实对象;
- 逻辑推论(Knowing):认识的充足理由律,适用于逻辑对象;
- 数学证明(Being):存在的充足理由律,解释时间和空间的必然性;
- 行为动机(Willing):行动的充足理由律,解释动机和行为之间的必然性。
经验主义
18 世纪,英国经验主义哲学家休谟将因果关系限定在了经验世界的具体对象中,先后在《人性论》和《人类理智研究》中给出了因果关系两个定义:
我们无从得知因果之间的关系,只能得知某些事物总是会连结在一起,而这些事物在过去的经验里又是从不曾分开过的。我们并不能看透连结这些事物背后的理性为何,我们只能观察到这些事物的本身,并且发现这些事物总是透过一种恒常的连结而被我们在想像中归类。
—— 休谟.人性论.1739
我们可以给一个因下定义说,它是先行于、接近于另一个对象的一个对象,而且在这里,凡与前一个对象类似的一切对象都和与后一个对象类似的那些对象处在类似的先行关系和接近关系中。或者,换言之,假如没有前一个对象,那么后一个对象就不可能存在。
—— 休谟.人类理解研究.1748
在《人性论》中,休谟对因果关系的客观性提出了怀疑,认为我们只能观察到事物本身及其恒常相继发生,并不能观察到事物背后的因果链接。在《人类理解研究》中,休谟提到了反事实推理的必要因,也即“若非因”。
经典力学
17 世纪,牛顿创立经典力学之后,决定论占据了所有学科领域的核心:万事万物都被包含在确定性的因果链条之中。法国数学家皮埃尔-西蒙·拉普拉斯在他的概率论导论中说:
我们可以把宇宙现在的状态视为其过去的果以及未来的因,假若一位智者知道在某一时刻所有促使自然运动的力和所有物体的位置,假若他也能够对这些数据进行分析,则在宇宙里,从最大的物体到最小的粒子,它们的运动都包含在一条简单公式里。对于这位智者来说,没有任何事物会是含糊的,并且未来只会像过去般出现在他眼前。
拉普拉斯这里所说的“智者”(intelligence)便是后人所称的拉普拉斯妖。
概率论
从赖欣巴哈和萨普斯开始,哲学家们开始使用“概率提高”的概念来定义因果关系:如果 X 提高了 Y 的概率,那么我们就说 X 导致了 Y,即 $P(Y|X) > P(X) => X \rightarrow Y$。这个概念也存在于我们的直觉中,并且根深蒂固。但是这种解释是错的,因为“提高”是一个因果概念,意味着 X 对 Y 的因果效应。但是,这种概率提高完全可能是其他因素造成的,比如 Y 是 X 的原因,或者其他变量是它们二者的原因。
18 世纪,一位英国长老会牧师和业余数学家托马斯·贝叶斯(Thomas Bayes),将概率现象解释为主观信念程度的变化和更新,让概率本身也失去了客观性。但自 19 世纪中叶起,随着频率学派(经典统计学派)的兴起,贝叶斯解释逐渐被统计学主流所拒绝。现代贝叶斯统计学的复兴肇始于 Jeffreys(1939),从 1950 年代开始,经过众多统计学家的努力,贝叶斯统计学才逐渐发展壮大。
在形式上,贝叶斯定理只是条件概率定义的一个初等推论,但在认识论上,它远远超出了初等的范畴。事实上,它作为一种规范性规则,能够用于根据证据更新信念这一重要操作。从许多层面来说,贝叶斯定理都是对科学方法的提炼:1. 提出一个假设 $h$;2. 推断假设的可检验结果;3. 进行实验并收集证据 $D$;4. 更新对假设的信念 $P(h|D)$。
贝叶斯定理所描述的仍然是“证据”和“假设”之间的相关性,证据所带来的“信念增强”并不意味着“证据”是“假设”的原因。
统计学
然而“除了物理学之外,都是集邮”(卢瑟福),纷纷效法物理学的其他自然和社会科学并没有取得想象中确定性的成功。到了19 世纪,统计学创始人高尔顿在研究“遗传均值回归”现象的过程中,以寻找因果关系为起点,最终却发现了相关性 —— 一种无视因果的关系。高尔顿的学生,作为统计学之父的卡尔·皮尔逊,则干脆用相关关系(Correlation)取代了因果关系,认为因果关系只是相关关系的一个特例。
我认为……高尔顿的本意是,存在一个比因果关系更广泛的范畴,即相关性,而因果关系只是被囊括于其中的一个有限的范畴。这种关于相关性的新概念在很大程度上将心理学、人类学、医学和社会学引向了数学处理的领域。
—— 皮尔逊.1934
一个特定的事件序列在过去已经发生并且重复发生,这只是一个经验问题,对此我们可以借助因果关系的概念给出其表达式……在任何情况下,科学都不能证明该特定事件序列中存在任何内在的必然性,也不能绝对肯定地证明它必定会重复发生。
—— 皮尔逊.科学语法.1892
皮尔逊将因果关系从统计学中剔除,取而代之的是相关关系。统计学告诉我们“相关关系不等于因果关系”,但并没有告诉我们因果关系是什么。在统计学教科书的索引里查找“因果”这个词是徒劳的。统计学不允许学生们说 X 是 Y 的原因,只允许他们说 X 与 Y “相关”或“存在关联”。统计学唯一关注的是如何总结数据,而不关注如何解释数据。
继高尔顿和皮尔逊之后,罗纳德·艾尔默·费舍尔成为当时统计学界无可争议的领袖,他简洁地描述了这种差异:
一旦你从统计学中删除因果关系,那么剩下的就只有数据约简了。
量子力学
进入 20 世纪,就连在物理学中人们也发现了更多不确定性现象。量子力学对微观世界的描述,让很多人确信,世界在根基上就是不确定性的。混沌理论革命则让人们意识到,对复杂系统即使存在确定的关系,也会因为初始敏感导致计算不可约性。
在这些科学发展的背景下,不确定性完全占据了上风,大多数人认为可能只存在相关性,在科学实践和决策上也广泛采取统计学方法。科学反映客观实在的观念已一去不复返,物理定律也降格为基于某种观测数据拟合的理论模型。
因果革命
2020 年 6 月 21 日,在第二届北京智源大会开幕式及全体会议上,图灵奖得主、贝叶斯网络奠基人Judea Pearl 做了名为《The New Science of Cause and Effect with reflections on data science and artificial intelligence》的主题演讲。
在演讲中,Judea Pearl 站在整个数据科学的视角,简单回顾了过去的“大数据革命”,指出数据科学正在从当前以数据为中心的范式向以科学为中心的范式偏移,现在正在发生一场席卷各个研究领域的“因果革命”。
To Build Truly Intelligent Machines, Teach Them Cause and Effect 。
——Judea Pearl
因果革命和以数据为中心的第一次数据科学革命,也就是大数据革命(涉及机器学习,深度学习机器应用,例如 Alpha-Go、语音识别、机器翻译、自动驾驶等等)的不同之处在于,它以科学为中心,涉及从数据到政策、可解释性、机制的泛化,再到一些社会科学中的基础概念信用、责备和公平性, 甚至哲学中的创造性和自由意志 。可以说, 因果革命彻底改变了科学家处理因果问题的方式。
Judea Pearl 认为,统计学的其他分支,以及那些依赖统计学工具的学科仍然停留在禁令时代,错误地相信所有科学问题的答案都藏于数据之中,有待巧妙的数据挖掘手段将其揭示出来。因果分析绝不只是针对数据的分析,在因果分析中,我们必须将我们对数据生成过程的理解体现出来,并据此得出初始数据不包含的内容。与相关性分析和大多数主流统计学不同,因果分析要求研究者做出主观判断。研究者必须绘制出一个因果图,其反映的是他对于某个研究课题所涉及的因果过程拓扑结构的定性判断,或者更理想的是,他所属的专业领域的研究者对于该研究课题的共识。为了确保客观性,他反而必须放弃传统的客观性教条。在因果关系方面,睿智的主观性比任何客观性都更能阐明我们所处的这个真实世界。
因果定义
数据科学所研究的因果关系是经验世界中事件之间的因果关系,正如休谟所言,在经验世界中,我们实际所能观测到的只是事件本身,而无法观测到隐藏在事件背后的“因果机理”,事件间的因果关系本质上是对事件序列间特定关系的概括性称谓。目前,一个被广泛接受的因果关系的定义是由 Lazarsfeld(1959)给出的:
如果变量 A 和变量 B 满足以下三个条件,则称 A 和 B 之间存在因果关系“A 导致 B”,其中 A 被称为 B 原因,B 被称为 A 的结果:
- A 在时间上必须先于 B;
- A 和 B 应当在经验上相互关联;
- A 和 B 之间观测到的经验相关不能被第三个导致 A 和 B 两者的变量所解释;
相关性只是因果性的一个必要非充分条件,即“相关性不一定意味着因果性”,A 和 B 相关可能是以下情形的结果:
- A 和 B 都由第三个变量 C 决定:如果通过控制 C,A 和 B 之间的相关性会消失,则说此相关是虚假的(spurious);比如“是否携带打火机”与“癌症发病率”之间的相关性,本质上是因为抽烟的人通常会携带打火机,并且癌症发病率更高所导致的;
- A 导致 B:我们对干扰变量进行了控制,但我们仍然观测到 A 和 B 之间高度相关;
- B 导致 A:相关性本身并没有告诉我们因果关系的方向;比如“公鸡打鸣”和“太阳升起”有高度相关性,但是统计数据本身并不能告诉我们到底是公鸡打鸣导致了太阳升起,还是太阳升起导致了公鸡打鸣;
至此,我们已经查勘了因果观念的全景,现在可以对数据科学所涉及到的因果关系概括如下:
在经验世界中,我们所能观察到的只是事件(数据)本身,而如果仅凭数据间的关联,我们只能得到事件间的相关性,事件间的因果关系是对事件序列特定关系的概括:如果 A 和 B 同时满足以下条件 ① A 在时间上先于 B;② A 和 B 在经验上相关;③ A 和 B 间的相关性不能被其他变量所解释;则称 A 是 B 的原因,或称 A 导致了 B。
因果推断(Causal Inference)
因果推断是研究变量间因果关系的学科,作为一门学科,因果推断目前仍然处于大众视野之外。朱迪亚·珀尔(Judea Pearl) 认为,一旦我们真正理解了因果思维背后的逻辑,就可以在现代计算机上模拟它,进而创造出一个“人工科学家”。这个智能机器人将会为我们发现未知的现象,解开悬而未决的科学之谜,设计新的实验,并不断从环境中提取更多的因果知识。
关于因果推断的讨论,可以有两个方向:
- 考察结果的原因:看到结果,寻找结果背后的原因,这种研究往往是科学的起点,但寻找结果背后的原因,非常复杂。某一种结果产生的原因可能有很多,需要通过详细的调查、深入的分析才能找到。
- 考察原因的结果:主要关注某一干预对结果的影响,一项干预对结果变量产生的影响,通常称为因果效应(causal effects)或干预效应(treatment effects)。
问题定义
按照所能回答问题的类型,Judea Pearl 将因果信息划分成了三个层级,其中,高层级信息可以回答低层级问题,但是低层级信息无法回答高层级问题:
| 层级 | 任务 | 活动 | 符号 | 问题 | 例子 | 评价 |
|---|---|---|---|---|---|---|
| 关联 | 基于被动观察做出预测 | 观察 | $P(Y\mid X)$ | 如果观察到X,如何预测Y? | 购买啤酒的用户多大可能会购买尿布? | 好的预测无需好的解释(因果) 当前机器学习/深度学习/统计学几乎完全是在关联层级下,由一系列观察数据拟合出一个函数 |
| 干预 | 基于主动干预做出评估 | 行动 | $P(Y\mid do(X))$ | 如果改变X,Y会怎样? | 如果价格提高两倍,销量会怎么变化? | 预测干预结果的方法是在严格控制的条件下进行实验 |
| 反事实 | 通过因果模型做出预测 | 想象 | $P(y_x \mid X’,Y’)$ | 假如观察到的不是X’,Y会怎样? | 假如过去没有抽烟,现在身体会更好吗? | 预测在尚未经历甚至未曾设想过的情况下会发生什么——这是所有科学的圣杯 |
Judea Pearl 在《The Book of Why》一书中对以上三种因果层级进行了详细描述,并将其称为“因果关系之梯”:
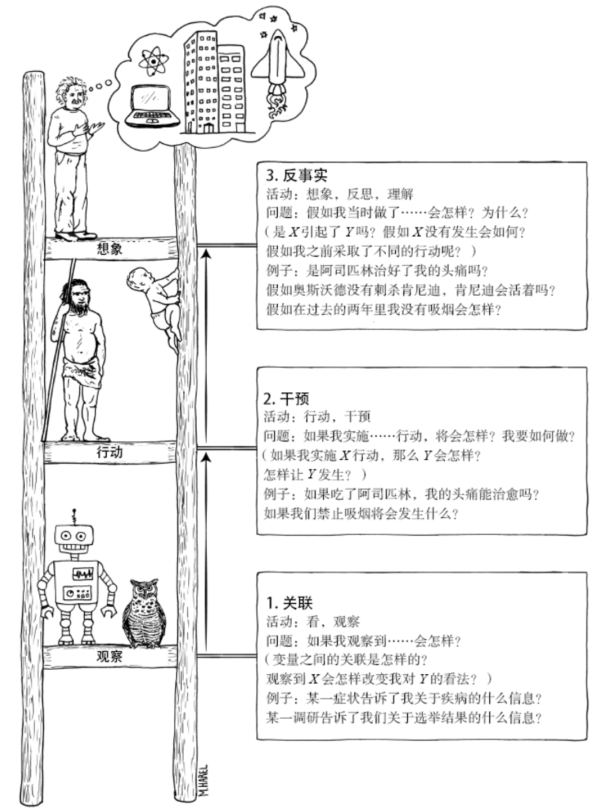
Judea Pearl 认为,人类的大脑拥有某种简洁的信息表示方式,同时还拥有某种十分有效的程序用以正确解释每个问题,并从存储的信息表示中提取正确答案,这就是因果图。Judea Pearl 通过一个被他称作“迷你图灵测试”的例子,借助因果图语言介绍了以上三种因果层级之间的差异。
如下图所示,假设一个犯人将要被执行枪决,这件事的发生必然会以一连串的事件发生为前提:首先,法院方面要下令处决犯人;命令下达到行刑队长后,他将指示行刑队的士兵(A 和 B)执行枪决;我们假设他们是服从命令的专业抢手,只听命令射击,并且只要其中任何一个抢手开了枪,囚犯都必死无疑。借助这个因果图,我们就可以回答来自因果关系之梯不同层级的因果问题了。
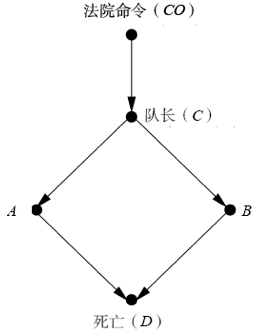
(1)首先,我们可以回答关联问题(一个事实告诉我们有关另一事实的什么信息)。一个可能的问题是,如果犯人死了,那么这是否意味着法院已下令处决犯人?我们(或一台计算机)可以通过核查因果图,追踪每个箭头背后的规则,并根据标准逻辑得出结论:如果没有行刑队队长的命令,两名士兵就不会射击。同样,如果行刑队队长没有接到法院的命令,他就不会发出执行枪决的命令。因此,这个问题的答案是肯定的。另一个可能的问题是,假设我们发现士兵 A 射击了,它告诉了我们关于 B 的什么信息?通过追踪箭头,计算机将断定B一定也射击了。(原因在于,如果行刑队队长没有发出射击命令,士兵A就不会射击,因此接收到同样命令的士兵B也一定射击了。)即使士兵 A 的行为不是士兵 B 做出某一行为的原因(因为从 A 到 B 没有箭头),该判断依然为真。
(2)沿着因果关系之梯向上攀登,我们可以提出有关干预的问题。如果士兵 A 决定按自己的意愿射击,而不等待队长的命令,情况会怎样?犯人会不会死?如果我们希望计算机能理解因果关系,我们就必须教会它如何打破规则,让它懂得“观察到某事件”和“使某事件发生”之间的区别。我们需要告诉计算机:“无论何时,如果你想使某事发生,那就删除指向该事的所有箭头,之后继续根据逻辑规则进行分析,就好像那些箭头从未出现过一样。”如此一来,对于这个问题,我们就需要删除所有指向被干预变量(A)的箭头,并且还要将该变量手动设置为规定值(真)。这种特殊的“外科手术”的基本原理很简单:使某事发生就意味着将它从所有其他影响因子中解放出来,并使它受限于唯一的影响因子——能强制其发生的那个因子。下图表示出了根据这个例子生成的因果图,显然,这种干预会不可避免地导致犯人的死亡,这就是箭头 A 到 D 背后的因果作用。同时,我们还能判断出:B(极有可能)没有开枪,A 的决定不会影响模型中任何不受 A 的行为的影响的其他变量。需要注意的是,仅凭收集大数据无助于我们登上因果关系之梯去回答上面的问题。假设你是一个记者,每天的工作就是记录行刑场中的处决情况,那么你的数据会由两种事件组成:要么所有 5 个变量都为真,要么所有都为假。在未掌握“谁听从于谁”的相关知识的情况下,这种数据根本无法让你(或任何机器学习算法)预测“说服枪手 A 不射击”的结果。
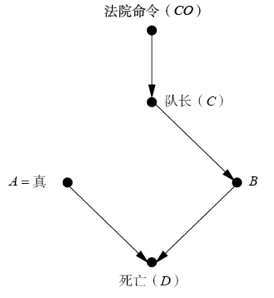
(3)最后,为了说明因果关系之梯的第三层级,我们提出一个反事实问题。假设犯人现在已倒地身亡,从这一点我们(借助第一层级的知识)可以得出结论:A射击了,B射击了,行刑队队长发出了指令,法院下了判决。但是,假如 A 决定不开枪,犯人是否还活着?这个问题需要我们将现实世界和一个与现实世界相矛盾的虚构世界进行比较。在虚构世界中,A 没有射击,指向 A 的箭头被去除,这进而又解除了 A 与 C 的听命关系。现在,我们将A的值设置为假,并让A行动之前的所有其他变量的水平与现实世界保持一致。如此一来,这一虚构世界就如下图所示。为通过迷你图灵测试,计算机一定会得出这样的结论:在虚构世界里犯人也会死,因为B会开枪击毙他。所以,A勇敢改变主意的做法也救不了犯人的命。

看起来,我们刚刚像是花了很大一番力气回答了一些答案显而易见的小问题。的确,因果推理对你来说很容易,其原因在于你是人类,在你还是三岁儿童时,你所拥有的功能神奇的大脑就比任何动物或计算机都更能理解因果关系。“迷你图灵问题”的重点就是要让计算机也能够进行因果推理,而我们能从人类进行因果推断的做法中得到启示。如上述三个例子所示,我们必须教会计算机如何有选择地打破逻辑规则。计算机不擅长打破规则,而这是儿童的强项。
数据来源
用于因果推断的数据来源一般有三种:
- 控制实验:对于实验组和控制组,严格控制混淆变量,结果的差异可以归因于原因变量的差异;控制实验对实验条件要求苛刻,一般用于自然科学研究领域;
- 随机实验:Fisher 认为我们不必控制其他变量差异,现实中也没有办法完全控制所有的其他变量,只要让随机机制决定干预变量的分配,就可以获得正确的因果效应;随机试验被称为因果推断的黄金标准;
- 观察实验:在很多场景下,尤其是在社会科学领域,我们既没有办法实施控制实验,也没有办法实施随机实验,只能获取到被动观察的自然数据;此时,可以通过一些近似手段模拟随机试验过程,进行因果推断;
理论基础
识别策略
参考
- Judea Pearl.The Book of Why: the new science of cause and effect
- 赵西亮.基本有用的计量经济学
- 罗素.西方哲学史
- 因果观念新革命?万字长文,解读复杂系统背后的暗因果
- Judea Pearl.The Seven Tools of Causal Inference, with Reflections on Machine Learning
- 图灵奖得主Judea Pearl:从“大数据革命”到“因果革命”
- Judea Pearl.The New Science of Cause and Effect with reflections on data science and AI 视频
- Foundations and new horizons for causal inference 研讨会, 2019(因果推断始于经济和生物统计等学科,它刚刚才开始成为人工智能的一个重要工具,数学基础依旧很零碎,该研讨会聚集了来自人工智能,生物统计学,计算机科学,经济学,流行病学,机器学习,数学和统计学的顶尖研究人员,研讨会上的报告和讨论将有助于在未来几年内塑造和改变这一领域的发展)
- Causality for Machine Learning, Bernhard Schölkopf, 2019(这是一篇刚刚挂 arxiv 就被 Pearl 亲自 twitter 点赞的论文,是马普智能所所长 Bernhard Scholkopf 最引以为傲的论文之一,他将被 Pearl 点赞这事情写在其个人主页自我介绍的第一段中。Scholkopf 及其团队在因果结合机器学习方面做了最多的工作,此文总结和升华了提出了信息革命时代下因果结合机器学习的一般理论和深刻思考)
- A Second Chance to Get Causal Inference Right: A Classification of Data Science Tasks, Miguel A. Hernán, John Hsu &Brian Healy, 2019(来自哈佛教授 Migual A. Hernan 对当前数据科学的深刻反思,澄清了数据科学任务如何分类的基本问题:prediction, deion and counterfactual prediction.)
- Causal Inference and Data-Fusion in Econometrics, P. Hünermund, E. Bareinboim.Dec, 2019.(该论文是因果革命,Pearl 的因果图模型框架如何影响某一个特定领域—计量经济学的范例)
