UGC(User Generated Content, 用户生成的内容)标签:当一个用户对一个物品打上一个标签,这个标签一方面描述了用户的兴趣,另一方面表示了物品的语义,从而将用户和物品联系起来。下图为豆瓣读书中《推荐系统实践》一书的常用标签。
本文主要探讨如何利用用户打标签的行为为其推荐物品。一个用户标签行为的数据集可以由一个三元组集合表示,其中每条样本(u,i,b)表示用户u为物品i打上了标签b。
标签作为特征/类别
可以将标签看做是LFM中的隐类(只不过这里是显式的),用户u对物品i的兴趣度可表示为:
- $n_{ub}$:用户u打过标签b的次数,可以看做是用户u对b类物品的喜好程度;
- $n_{bi}$:物品i被打过b标签的次数,可以看做物品i属于b类的”概率“;
仔细研究以上公式可以发现以下缺点:
- 热门标签给$n_{ub}$的权重很大;
- 热门物品给$n_{bi}$的权重很大;
借鉴TF-IDF的思路,可以通过惩罚用户或物品中热门标签的方式来优化以上公式:
- $1+n_b^u$:标签b被多少个用户使用过
- $n_i^u$:物品i被多少个用户打过标签
标签的稀疏性:对于新用户或新物品,集合$B(u)\bigcap B(i)$中的标签数量很少。
标签扩展:为提高推荐准确率,需要对标签集合进行扩展,如果用户使用过某个标签,我们可以将与这个标签相似的标签也加入到用户标签集合中去。扩展标签的方式有很多,常用的有话题模型,这里介绍一种基于邻域的方法,核心是计算标签之间的相似度。
标签相似度:可以用两个标签下物品的重合度来度量它们的相似度
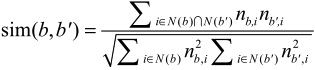
基于图的推荐
定义用户-物品-标签三分图:图中有三种顶点,即用户顶点、物品顶点、标签顶点,如果一个用户u给物品i打了标签b,则在图中添加三条边(u,i)、(u,b)、(i,b)。
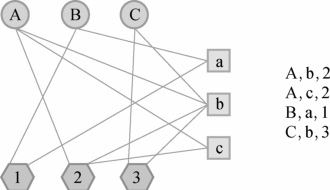
然后使用类似于二分图中随机游走的方式计算出所有物品相对于当前用户节点的相关性,排序后为用户推荐排名最高的K个物品。
